Couple of months ago I was asked to design and implement a new feature for one of the customer's applications that involved calls to 3rd party services, including on-premise ones, and orchestration of those calls. The application I am talking about is hosted on AWS and implemented using AWS Serverless stack (Lambda, DynamoDB, Glue, etc). In this article I will explain the proposed solution as well as its pros, cons and things to be careful about, especially if you work with large enterprises. Looking ahead, I can tell that this problem has been solved using AWS Step Function in a tandem with AWS API Gateway and Lambdas.
Problem to solve
Unfortunately, I cannot disclose any details of the problem I was solving. However, I can share a very similar example. Imagine that we have a serverless (FAAS) or microservices application on AWS that contains a set of Lambda Functions or EKS/ECS services, which pull a pre-populated (by ETL) information from the DB to send it on UI to be rendered. There is one service that has a related to it UI page and provides information about our products based on user ID and this information includes price, description, etc. To make the explanation simpler and avoid iterations we can assume that this service returns only one product per user.
After having this service in production for some time we received a new requirement from the business team saying that we have to take a product SKU retrieved from our service and call an external API to get availability of the current product in each of our warehouses. During your conversation, they briefly mentioned that in future we may also need to call other APIs, for example, to check if the current user/product combination is eligible to finance the purchase. So, the target state sequence may look like the following.
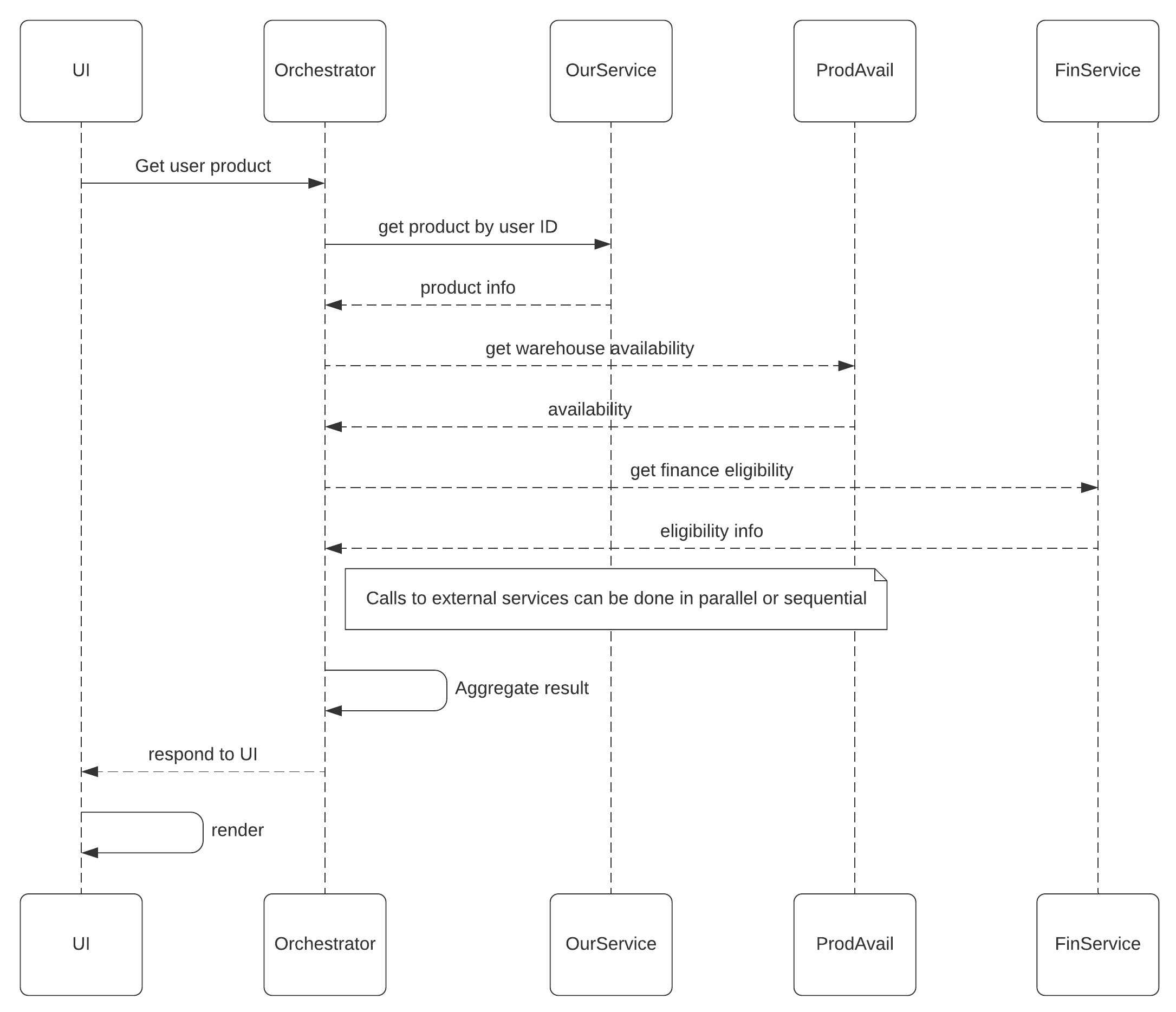
I guess the first thing many of us would think about in this scenario is either some kind of orchestration service or BFF (even though it is not an exact use-case for it), or maybe even choreography. However, each of these approaches has its own advantages and disadvantages, for example, this article claims that orchestration may eventually evolve into a distributed monolith. The same can be true for BFF, so BFF is not always a best friend forever. Choreography with Event Broker can help avoiding mentioned issues, but can also be quite inconvenient and difficult to implement.
The alternative solution is AWS Step Functions Expess which is lightweight, extensible, serverless and can be much cheaper than all the alternatives mentioned above. So, today we are going to discuss orchestration using Step Functions, but before we proceed let's find out what the Step Functions is.
What is a Step Function and what does Express mean?
According to AWS description Step Functions is:
a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications. Workflows manage failures, retries, parallelization, service integrations, and observability so developers can focus on higher-value business logic.
In two words it is a serverless low-code orchestration tool. Step Functions were originally designed to orchestrate long-running processes, which is not exactly what we need to orchestrate HTTP calls. However, in the end of 2019 AWS released AWS Step Functions Express Workflows that are designed to orchestrate events such as HTTP calls and other. As you could guess by now, it is exactly what we need.
High level architecture
Considering that Step Functions cannot be called directly over HTTP we have to use a middleman in the form of API Gateway to proxy requests between consumers (in our case - UI) and the Step Function. All the orchestration logic will be implemented in the Step Function itself using Amazon States Language or, in short, ASL, which is a JSON-like language created by Amazon to describe orchestration workflows.
Another issue we need to overcome is related to the Step Function and the fact that it can't call an external APIs by itself (only AWS integrations are currently supported), so we need to use AWS Lambda as a helper.
To make the architecture complete, we also need to think about the database. In a real life you must always make your decisions based on requirements, so let's mimic that as well. Our requirements are quite vague, but we know that the only function our internal service performs is returning pre-populated product details by user ID. It means that we do not need to perform any complex queries and the data can be represented in a JSON format. We know nothing about scalability requirements, transactions, etc., so we can assume that our database serves as a read-only information provider and the system must survive during the peak hours. Considering all the assumptions and facts mentioned earlier I would probably consider AWS DynamoDB as a database choice for this solution (but watch out for Potential Pitfalls With DynamoDB when you are using it in a real life). As a result, our architecture may look like the following.
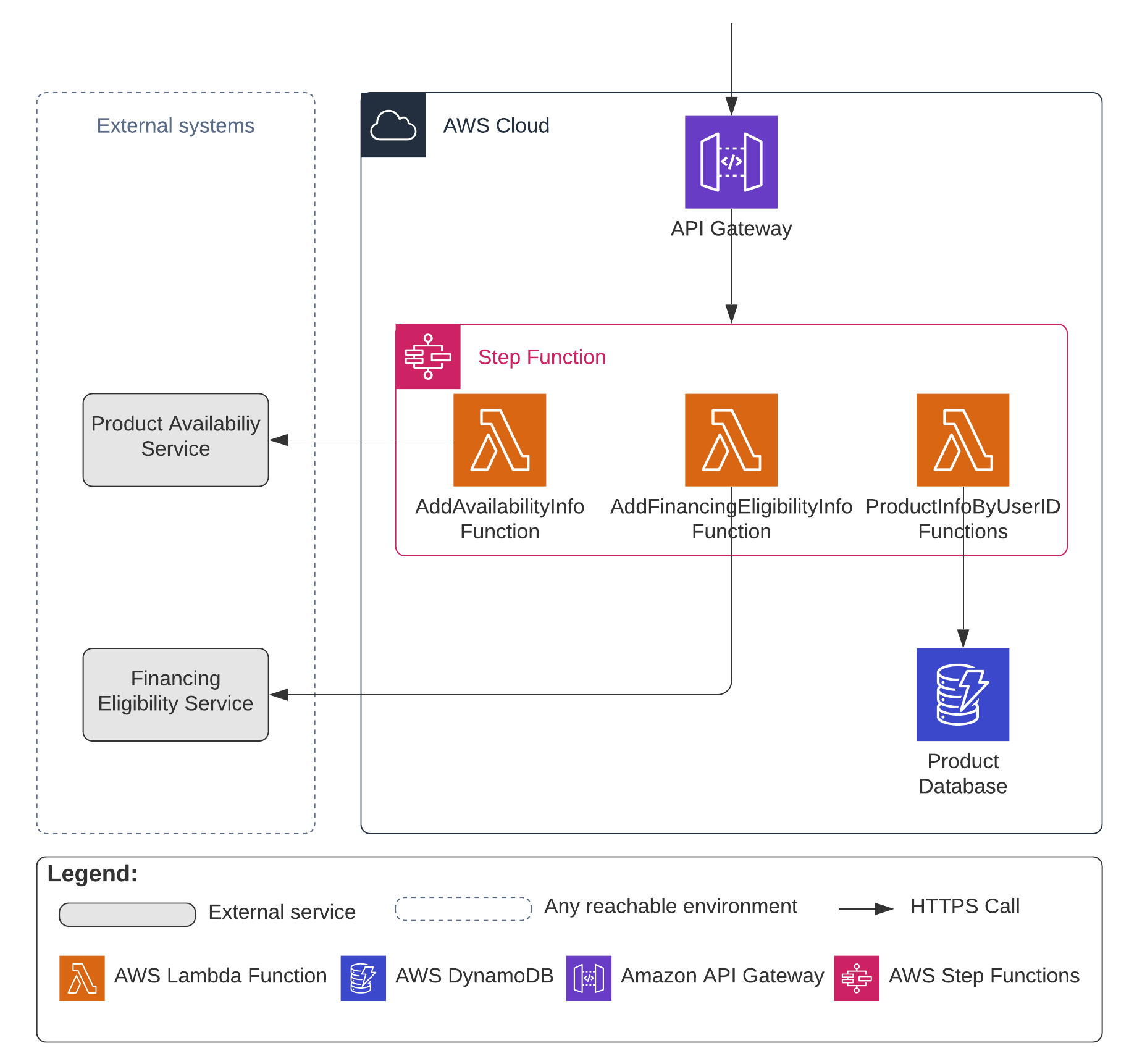
Now, when we know what our system will look like conceptually, we can discuss the implementation details.
Implementation
Since we are talking about the whole architecture, then why don't us implement it fully?! There are many ways on how to create a cloud infrastructure and deploy your code, but I decided to use AWS CloudFormation (CF) as a tool of choice. Therefore, going forward we can assume that the whole infrastructure is deployed using CloudFormation.
Spoiler: Complete code example is available on my GitHub.
We have already discussed that our backend can be almost anything, so for the sake of simplicity I have chosen Lambda functions. However, before jumping into coding, let's think ahead. As we know, step functions are defined using JSON-based ASL and in order to integrate a step function with other AWS services we need to either hard-code their ARNs or pass ARNs as a parameter to the step function (SF) and then use them dynamically inside the function. Considering this fact and a lack of time, I decided to use static approach and split deployment into two phases:
- Deployment of DynamoDB and Lambda functions
- Deployment of API Gateway and Step Function
Hint: Alternative way I have been thinking about is to create two CF templates, one for lambda deployment and one for step functions. Implement Step Function to get ARNs from parameters and configure Step Function template to use outputs of Lambda template. Additionally configure AWS Api Gateway request mapping to add static fields with ARNs into request (taken from Lambda template output) to pass it to the Step Function in an invisible for the API consumer way. I haven't tried this approach yet, but I think it should work. Please let me know in the comments below if you did something like that.
AWS Lambda & Dynamo DB
The only fully independent thing on our architecture is DynamoDB, so it would be reasonable to start with it. DynamoDB is key-value (often used as document one) database, which means it doesn't have a predefined schema, thus when we create a new DynamoDB table the bare minimum we need to specify is key fields. As we know, our table must return product information based on user identifier, so it makes sense to choose user as a partition key.
We may also consider defining the product name as a sorting key for this table, but it is unnecessary for this example.
Here is the CloudFormation template code we will be using to create mentioned table:
"ProductTable": {
"Type": "AWS::DynamoDB::Table",
"Properties": {
"TableName": "product",
"BillingMode": "PAY_PER_REQUEST",
"AttributeDefinitions": [
{
"AttributeName" : "user",
"AttributeType" : "N"
}
],
"KeySchema": [
{
"AttributeName" : "user",
"KeyType" : "HASH"
}
]
}
}Lambda function creation is a bit more complicated as except infrastructure it requires us creating the function logic itself. In this example I am going to use Python to define the logic.
Considering that Financing Eligibility Function and Availability Functions will be used for demonstration purposes only, we can simply return some random response.
Availability function:
import os
import json
import random
def lambda_handler(event, context):
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"Available": bool(random.getrandbits(1))
})
}Financing Eligibility Function:
import os
import json
import random
def lambda_handler(event, context):
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"Eligible": bool(random.getrandbits(1))
})
}To be able to deploy these two functions we need to place the zip-compressed code into S3 bucket. Deployment template for these functions will look like following.
"FinServiceLambda": {
"Type" : "AWS::Lambda::Function",
"Properties" : {
"FunctionName": "FinServiceFunction",
"Runtime": "python3.8",
"PackageType": "Zip",
"Handler": "fin_function.lambda_handler",
"Code": {
"S3Bucket" : {
"Ref": "CodeBucket"
},
"S3Key": {
"Ref": "FinServiceLambdaS3FilePath"
}
},
"Role": {
"Fn::GetAtt": [
"LambdaRole",
"Arn"
]
}
}
},
"AvailabilityServiceLambda": {
"Type" : "AWS::Lambda::Function",
"Properties" : {
"FunctionName": "AvailabilityServiceFunction",
"Runtime": "python3.8",
"PackageType": "Zip",
"Handler": "availability_function.lambda_handler",
"Code": {
"S3Bucket" : {
"Ref": "CodeBucket"
},
"S3Key": {
"Ref": "AvailabilityServiceLambdaS3FilePath"
}
},
"Role": {
"Fn::GetAtt": [
"LambdaRole",
"Arn"
]
}
}
}This template contains parameters to tell the template where the code is located. Another thing that we didn't discuss yet is "Role", but don't worry, we will get there.
The third function is a bit more complex as it needs to access DynamoDB, so its code looks as follows.
import os
import json
import boto3
from decimal import Decimal
class DecimalEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, Decimal):
return str(obj)
return json.JSONEncoder.default(self, obj)
def lambda_handler(event, context):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('product')
try:
response = table.get_item(
Key={
'user': event['user']
}
)
item = response['Item']
except:
item = 'Not found'
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps(item, cls=DecimalEncoder)
}And here is the deployment template for it.
"ProductServiceLambda": {
"Type" : "AWS::Lambda::Function",
"Properties" : {
"FunctionName": "ProductServiceFunction",
"Runtime": "python3.8",
"PackageType": "Zip",
"Handler": "product_function.lambda_handler",
"Code": {
"S3Bucket" : {
"Ref": "CodeBucket"
},
"S3Key": {
"Ref": "ProductServiceLambdaS3FilePath"
}
},
"Role": {
"Fn::GetAtt": [
"LambdaRole",
"Arn"
]
}
}
}However, the execution of this function will fail if we don't provide it with proper permissions, i.e. we need to create a Role. For simplicity I am using the same role for all functions.
"LambdaRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
"Path": "/",
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AWSLambdaDynamoDBExecutionRole",
"arn:aws:iam::aws:policy/AmazonDynamoDBReadOnlyAccess"
]
}
}Full template is here. If you want to play with these functions in your account, you need to upload Zip archives into an S3 bucket within the same account and provide bucket name as well as names of archives as parameters to a CloudFormation Stack.
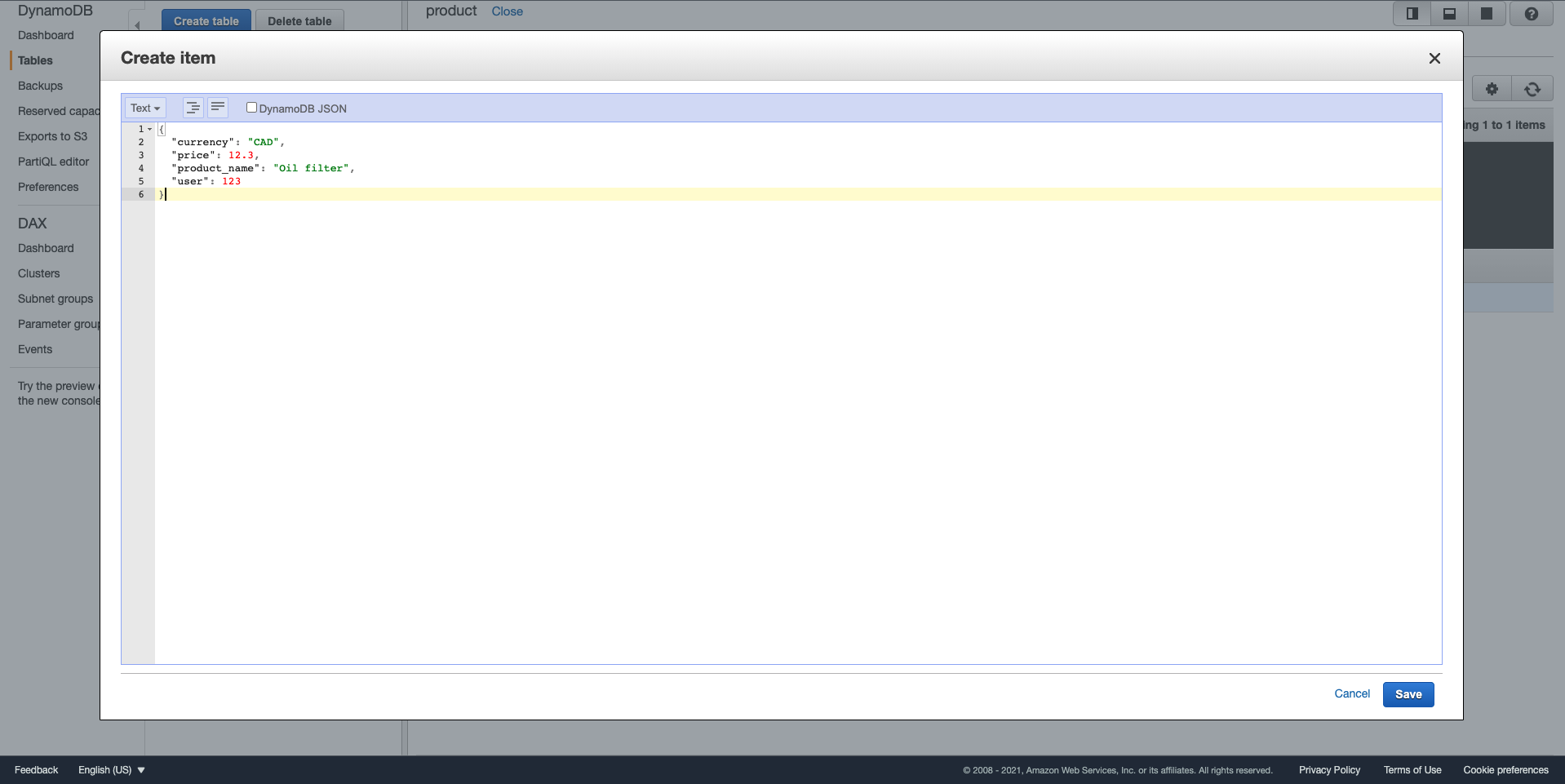
Once DynamoDB and Lambda functions are deployed we need to put some data into the DynamoDB table, so we can use it for tests later. To add it you need to navigate to the DynamoDB console, select the "product" table, click "Create item" and add the data. I prefer using Text format like shown on a screenshot below.
For your convenience the stack returns an output once completed. In my case the output contains lambda ARNs as shown on a screenshot below.
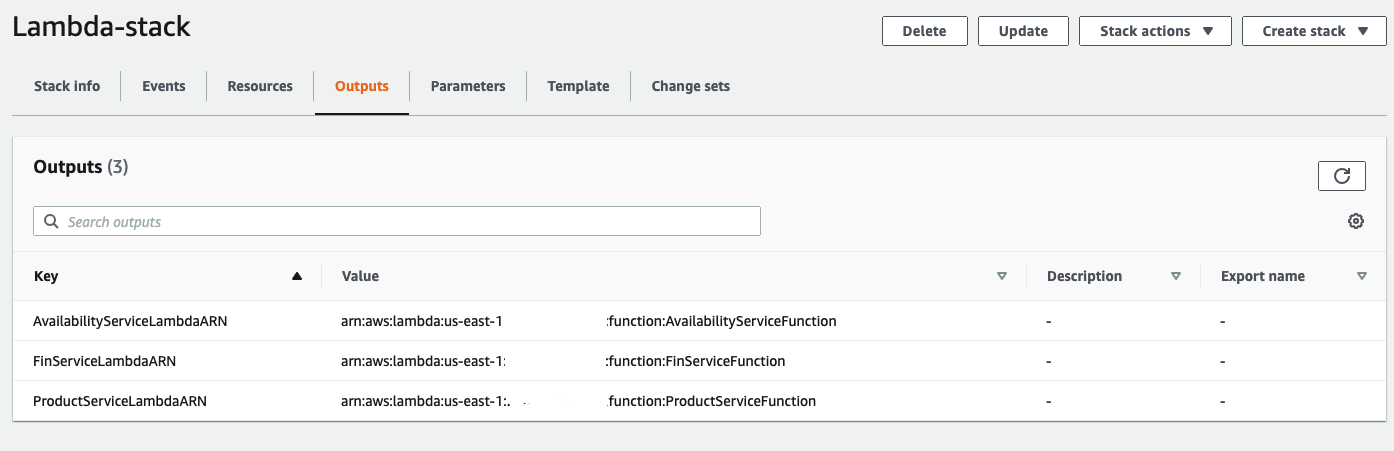
ApiGateway & Step Functions
Now, when our backend functions are ready, we can proceed with orchestration. First of all, we have to create a Step Function, and to do that right we need to stop for a moment and think about initial requirements. It was stated that we expect to get information about product as well as its availability and financing eligibility all in one response, which means that we need to call Product Function first, remember its result and then use it to call Availability and Financing Eligibility Functions. Once all results are retrieved, we need to aggregate them in a single response and return to a client. With that said, my step function design looks like the following.
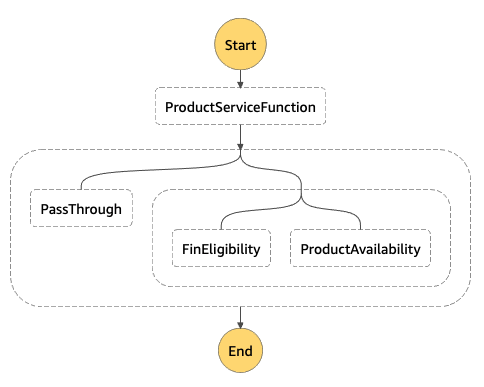
It assumes that we perform the first call to ProductServiceFunction, then we start two parallel branches: PassThrough - to remember the result of Product Service Function, and two other parallel branches to call Availability and Financing Eligibility functions. As a result, Step Function will aggregate responses of all three branches into an array and return it as a single response. The implementation of such a function looks like the following.
{
"Comment": "Product Orchestration Step Function",
"StartAt": "ProductServiceFunction",
"States": {
"ProductServiceFunction": {
"Type": "Task",
"Resource": "{LambdaARN}",
"Parameters": {
"user.$": "$.user"
},
"OutputPath": "$.body",
"Next": "Orchestration"
},
"Orchestration": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "PathThrough",
"States": {
"PathThrough": {
"Type": "Pass",
"End": true,
"ResultPath": null
}
}
},
{
"StartAt": "SupplementaryFunctions",
"States": {
"SupplementaryFunctions": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "FinEligibility",
"States": {
"FinEligibility": {
"Type": "Task",
"Resource": "{LambdaARN}",
"OutputPath": "$.body",
"End": true
}
}
},
{
"StartAt": "ProductAvailability",
"States": {
"ProductAvailability": {
"Type": "Task",
"Resource": "{LambdaARN}",
"OutputPath": "$.body",
"End": true
}
}
}
]
}
}
}
]
}
}
}Please replace {LambdaARN} with real ARNs of your functions.
To deploy the Step Function using Cloud Formation we need to upload the code into S3 bucket within the same account and create a deployment template like the one below.
"OrchestratorStepFunction": {
"Type": "AWS::StepFunctions::StateMachine",
"Properties": {
"StateMachineName": "Orchestrator-StateMachine",
"StateMachineType": "EXPRESS",
"DefinitionS3Location": {
"Bucket" : {
"Ref": "CodeBucket"
},
"Key" : {
"Ref": "StepFunctionS3FilePath"
}
},
"RoleArn": {
"Fn::GetAtt": [
"StepFunctionRole",
"Arn"
]
}
}
}CodeBucket and StepFunctionS3FilePath are CloudFormation Stack parameters.
As you can see Step Function, as almost any other service, does require its own set of permissions, so we need to define a role as well.
"StepFunctionRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "states.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
"Path": "/",
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AWSLambdaRole"
]
}
}Once we have the code uploaded to S3 and Step Function deployment template defined, we can start thinking about Api Gateway, which will be deployed using CloudFormation as well.
"StepFuncGateway": {
"Type": "AWS::ApiGatewayV2::Api",
"Properties": {
"ProtocolType": "HTTP",
"Name": "StepFuncGatewayApi"
},
"DependsOn": [
"OrchestratorStepFunction"
]
}DependOn section defines the sequence of provisioning.
Api Gateway is a bit tricky to configure as apart of defining the gateway itself, we need to integrate it with our step function.
"StepIntegration": {
"Type": "AWS::ApiGatewayV2::Integration",
"Properties": {
"ApiId": {
"Ref": "StepFuncGateway"
},
"Description": "StepFunction integration",
"IntegrationType": "AWS_PROXY",
"IntegrationSubtype": "StepFunctions-StartSyncExecution",
"ConnectionType": "INTERNET",
"PassthroughBehavior": "WHEN_NO_MATCH",
"PayloadFormatVersion": "1.0",
"CredentialsArn": {
"Fn::GetAtt": [
"APIGatewayRole",
"Arn"
]
},
"RequestParameters": {
"Input": "$request.body",
"StateMachineArn": {
"Fn::GetAtt": [
"OrchestratorStepFunction",
"Arn"
]
}
}
},
"DependsOn": [
"StepFuncGateway"
]
}Note: I am using AWS Api Gateway V2 because the CloudFormation template for Api Gateway V1 doesn't support the "IntegrationSubtype" tag yet. It is still possible to use it, but integration will be defined using OpenAPI (Swagger) definition. We will get back to it in the Pros & Cons section.
However, the integration on itself only defines the connection between services, which means that to have a proper externally callable URL we need to define a route.
"StepRoute": {
"Type": "AWS::ApiGatewayV2::Route",
"Properties": {
"ApiId": {
"Ref": "StepFuncGateway"
},
"RouteKey": "POST /step",
"Target": {
"Fn::Join": [
"/",
[
"integrations",
{
"Ref": "StepIntegration"
}
]
]
}
},
"DependsOn": [
"StepFuncGateway",
"StepIntegration"
]
}DependsOn section is unnecessary here, but I like to keep it for my own visibility.
The last, but not least is to create Api Gateway stage and deployment that deploys our RestApi to a stage.
"ApiDeployment": {
"Type": "AWS::ApiGatewayV2::Deployment",
"DependsOn": [
"StepRoute"
],
"Properties": {
"Description": "My deployment",
"ApiId": {
"Ref": "StepFuncGateway"
}
}
},
"MyStage": {
"Type": "AWS::ApiGatewayV2::Stage",
"Properties": {
"StageName": "Prod",
"Description": "Prod Stage",
"DeploymentId": {
"Ref": "ApiDeployment"
},
"ApiId": {
"Ref": "StepFuncGateway"
}
},
"DependsOn": [
"StepFuncGateway",
"ApiLogGroup"
]
}And, as everything else, our Api Gateway needs our permission to call the Step Function, so let's create a Role.
"APIGatewayRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"apigateway.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
},
"Path": "/",
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs",
"arn:aws:iam::aws:policy/AWSStepFunctionsFullAccess"
]
}
}Full version of Step Function & ApiGateway template is here.
Once deployed you can navigate to the Api Gateway console and capture the invoke URL.
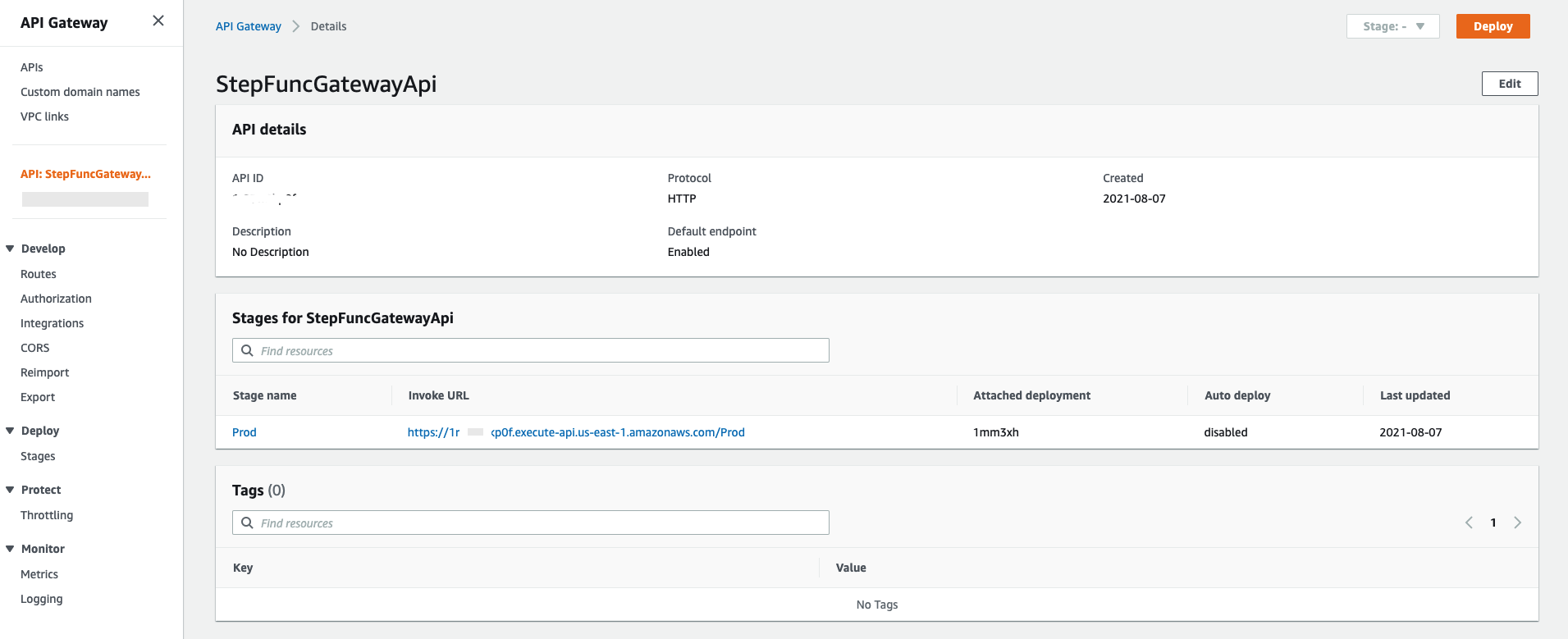
This is the base URL that will be used to call our orchestration, but we also need to add a route in the end to make the URL complete.
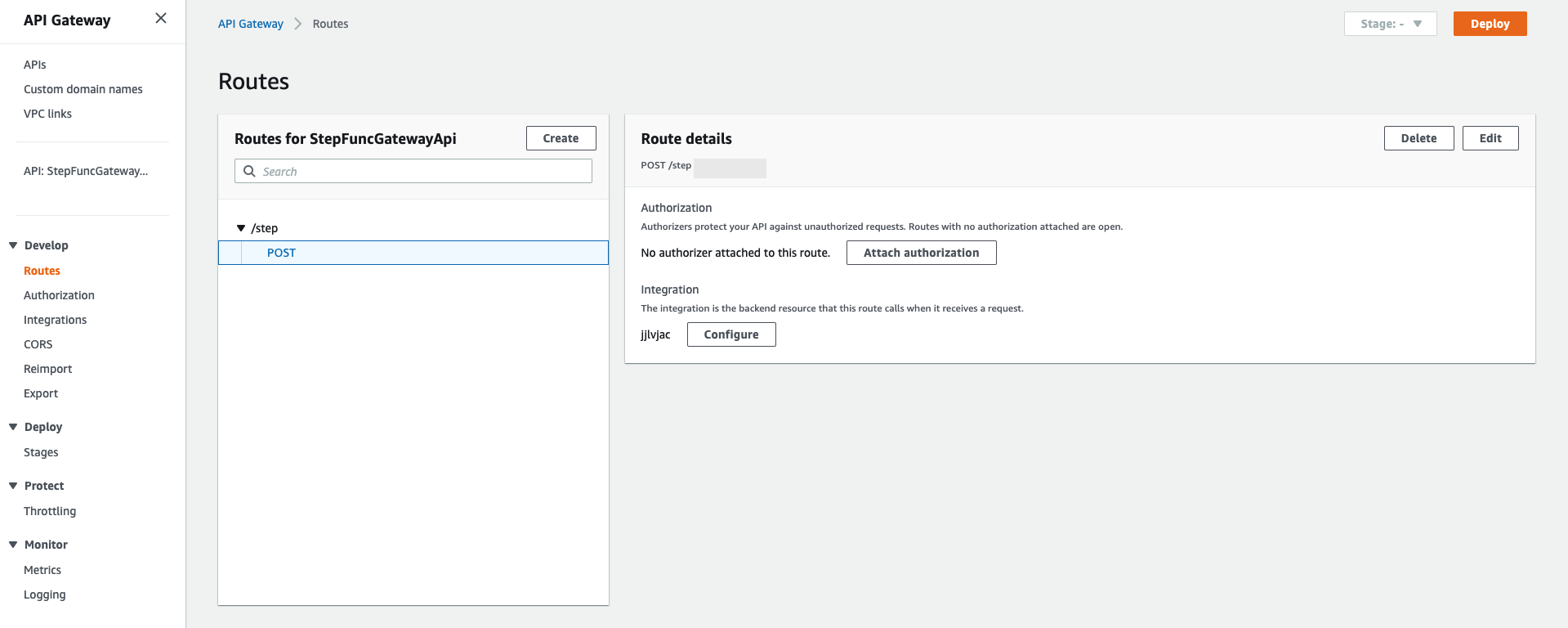
Do not forget that in the beginning of this article we created one record in the DynamoDB Table with 'user = 123', so why don't us use it to make a request?
curl --location --request POST 'https://{API_ID}.execute-api.{REGION}.amazonaws.com/Prod/step' \
--header 'Content-Type: application/json' \
--data-raw '{
"user": 123
}'Note: Replace https://{API_ID}.execute-api.{REGION}.amazonaws.com/Prod/step with your URL.
In this example we are using CURL to make a request, but it can be done using any client, for example, Postman.
This request should return the response similar to the one below.
{
"billingDetails": {
"billedDurationInMilliseconds": 300,
"billedMemoryUsedInMB": 64
},
"executionArn": "arn:aws:states:...:...:express:Orchestrator-StateMachine:658ce671-afb8-4fa9-bc3b-8a9eb7e03a7b:ae2fac14-cad2-43e7-87b6-8726594fbbcf",
"input": "{\n \"user\": 123\n}",
"inputDetails": {
"__type": "com.amazonaws.swf.base.model#CloudWatchEventsExecutionDataDetails",
"included": true
},
"name": "658ce671-afb8-4fa9-bc3b-8a9eb7e03a7b",
"output": "[\"{\\\"user\\\": \\\"123\\\", \\\"currency\\\": \\\"CAD\\\", \\\"price\\\": \\\"12.3\\\", \\\"product_name\\\": \\\"Oil filter\\\"}\",[\"{\\\"Eligible\\\": true}\",\"{\\\"Available\\\": true}\"]]",
"outputDetails": {
"__type": "com.amazonaws.swf.base.model#CloudWatchEventsExecutionDataDetails",
"included": true
},
"startDate": 1.628360949305E9,
"stateMachineArn": "arn:aws:states:...:...:stateMachine:Orchestrator-StateMachine",
"status": "SUCCEEDED",
"stopDate": 1.628360949654E9
}In this response we have an output field which contains stringified JSON with the information about our product, its availability and financing eligibility.
[
{
"user": "123",
"currency": "CAD",
"price": "12.3",
"product_name": "Oil filter"
},
[
{
"Eligible": true
},
{
"Available": true
}
]
]As you can see, it works quite fast and does exactly what we need. On this positive note it is time to finish the implementation section and discuss all the pros and cons of step functions orchestration method.
PS: The code here might not be ideal and serves the demonstration purposes only. If you have improvement ideas, free time and willingness to contribute, please leave the comment below and/or create a pull request to my GitHub repo.
Pros & cons
Let's start with the benefits of this approach:
- AWS Native & Serverless - AWS native serverless technologies bring a lot of benefits including:
- Cheap - serverless is usually very cheap, unless you have billions of executions. Moreover, most of AWS services have a free tier. For example, the first one million Lambda executions per month if free.
- Scalable - all technologies used in this example scale extremely well and what's important - they do it automatically, which leads us to the next point.
- No infrastructure to manage - as the name serverless suggests - you do not need to manage servers. However, it doesn't mean that there are no servers at all, it just means that servers are managed by AWS in a way invisible for you.
- Flexible - the Step Function is a low-code technology and is purely based on JSON configuration. It integrates with many AWS services, and those it doesn't integrate with can still be integrated using Lambda as a proxy.
As almost everything in this world, this approach has its own downsides as well:
- Vendor lock - all serverless technologies are usually native to clouds, which means if you want to move it to another cloud - you need to recreate it from scratch.
- New skills required - serverless design paradigms are quite different from what many people used to. In the case of Step Functions you also need to learn ASL, so you should plan project activities accordingly.
- Warm up - many serverless technologies need to stay "warm", i.e. be used often, otherwise they may go to idle state and the processing time for the first request from idle state will take longer (or as I observed with Step Functions, it may simply fail, but retry helps).
There are many more points to discuss, but the mentioned ones are the most important from my point of view.
Real-life difficulties
During my time with step functions I faced a couple of difficulties that I had to overcome and I sincerely hope my experience will make your life easier. The following list is unordered, thus there is no number one or anything like that.
Java payload emulation
If your language of choice for AWS Lambda is Java you may need to use AWS SDK to parse request information and, most likely, you will be using aws-serverless-java-container-core library to parse incoming requests. This library has a class AwsProxyHttpServletRequestReader which contains the following function.
public AwsProxyHttpServletRequest readRequest(AwsProxyRequest request, SecurityContext securityContext, Context lambdaContext, ContainerConfig config)This function assumes that the request has a set of mandatory fields that includes: HttpMethod, RequestContext and some other. All of this means that if we call such a function from the Step Function it would simply fail with a validation error. To overcome this issue you may want to emulate a payload sent by Api Gateway by structuring your parameter set like following.
"TaskThatCallsLambda": {
"Type": "Task",
"Resource": "{LambdaArn}",
"Parameters": {
"path.$": "States.Format('/stage/example/path/{}/{}', $.fst_param, $.snd_param)",
"resource": "/stage/example/path/{fst_param}/{snd_param}",
"httpMethod": "GET",
"pathParameters": {
"fst_param.$": "$.fst_param",
"snd_param.$": "$.snd_param"
},
"multiValueHeaders.$": "$.multiValueHeaders",
"requestContext": {
"identity": {
"userArn": "fake_arn",
"accessKey": "FAKE_ACCESS_KEY",
"user": "api_gateway",
"accountId": "123456789012"
},
"path.$": "States.Format('/stage/example/path/{}/{}', $.fst_param, $.snd_param)",
"resourcePath": "/stage/example/path/{fst_param}/{snd_param}",
"httpMethod": "GET",
"protocol": "HTTP/1.1"
}
}As you can see, we are providing some extra information to satisfy the validation logic and sometimes this information is a complete fake.
Note: This example relates to request v1. Version two is pretty similar, but has its own set of fields to validate.
Api Gateway V1
As I mentioned before, CloudFormation templates for Api Gateway V1 do not support IntegrationSubtype tag, which means that in order to implement integration between Api Gateway V1 and Step Function you need to use OpenApi definition. Usually such definitions are stored separately, which complicates the infrastructure code, maintenance and deployment.
You might be wondering why I would use the Api Gateway V1 then? And this brings us to the next point.
Resource Policy & API Keys
Api Gateway V2 is newer, but it is quite limited in its functions. For instance, it doesn't support API Keys that are important for many enterprises.
Another tricky moment is related to Resource Policies and the fact that Api Gateway V2 doesn't support them as well. In my case it was a big deal as the client's security standard was to whitelist IP addresses using this method and the only workaround we could find is to use AWS Web Application Firewall, which introduces additional cost and increases infrastructure complexity.
CloudFormation Update
As it is stated in the AWS documentation when we update CloudFormation stack it must update the Step Function with no interruption. However in practice it does update the definition of Step Function, but the working instance remains the same, so you might want to delete the stack and deploy it again.
The same thing happens with Api Gateway, but with it you have a workaround. You can simply create a new deployment and repoint your stage to it.
String response
Last but not least. As shown previously, Step Function returns the JSON, but the output field in this response is a stringified JSON, which is not what a normal person would expect to get, so you may want to unstringify it on a client side. However the hope is not dead since AWS is already trying to fix it by introducing startExecution.sync:2.
Conclusion
Serverless technologies bring a lot of benefits, and at the same time they impose limitations that are critical for many workloads. Serverless might sound innovative and "sexy" (the same thing happened with microservices some time ago) and, as you could see, they are really cool in practice too. Buzzwords are always in trend, but you should not forget that it is your accountability and your choice whether to make those tradeoffs. Make sure to do an unopinionated comparison of different options based on their qualities and choose the best one based on requirements rather than on your personal preferences.