
Amazon DynamoDB has been around for quite a while and it became a standard for many AWS architectures. Amazon positions this database as a universal tool that is able to solve almost any problem, with only minor exceptions. As a result, it became a "no-brainer" choice for many people, and I get it! They admire DynamoDB for its simplicity, out-of-the-box scalability, single milliseconds response time, cost and other useful features. However, we should always be careful as the "silver bullet" for databases has not been invented yet. So, in this article we are going to discuss some hidden traps which you can fall into with DynamoDB if you don't choose it carefully.
DynamoDB Overview
According to Amazon Website Dynamo DB works as both, key-value and document database, which is true, however, under the hood it behaves more like a key-value storage than anything else. For instance, there are only one or maximum two attributes that DynamoDB cares about, namely: partition key and sort key. As you could guess by their names, partition key defines partition where the item (this is how DynamoDB "record" is called) should be stored and sorting key defines how items are sorted.
All items with the same partition key are stored together, and for composite partition keys, are ordered by the sort key value. DynamoDB splits partitions by sort key if the collection size grows bigger than 10 GB. (C) Amazon Blog
Such design makes the database quite flexible as there is no common schema for the items stored in it. So, to create a new DB table you simply need to tell DynamoDB the names of your key attribute(s) and their type. That's it... Which means that your data needs to have only one or two attributes that will be common for all items, everything else can be different.
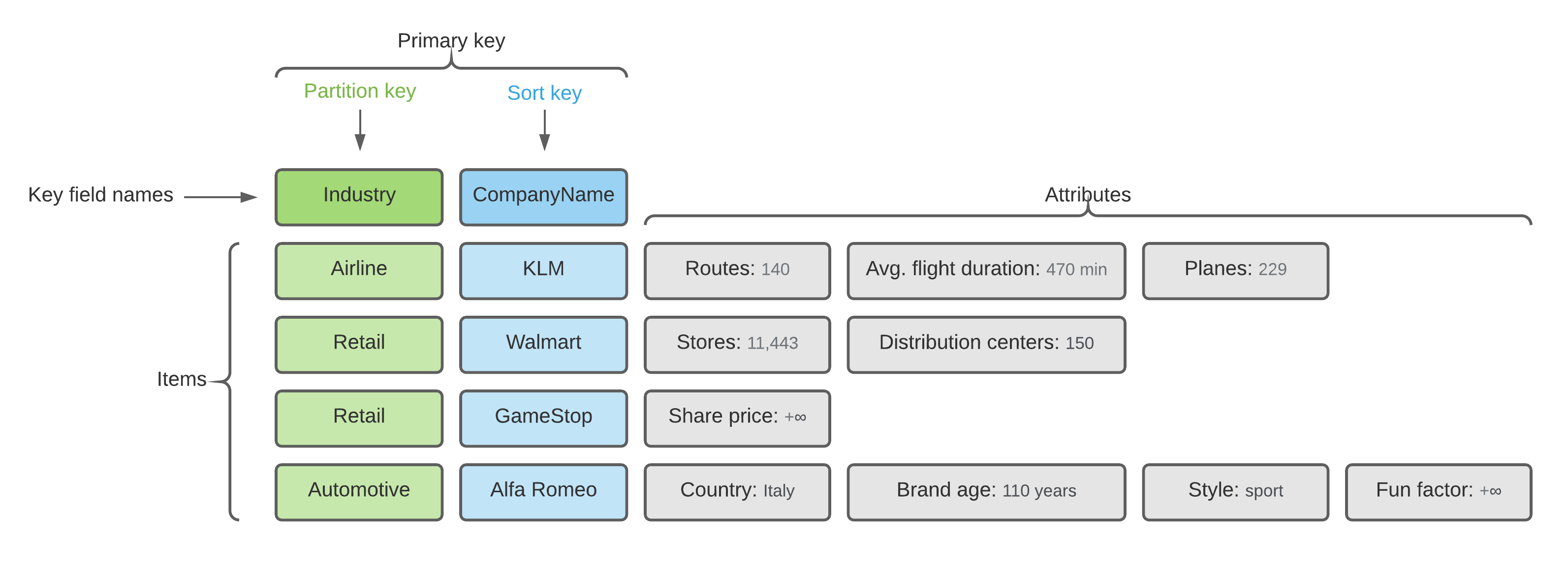
However, this flexibility comes with its own price, so let's discuss some of the potential pitfalls that you can encounter while working with DynamoDB.
User experience example
Sometimes we need to build simple applications that emphasize user experience. For example, let's imagine that we have a DynamoDB table which stores registered users and we are building an admin page for a website where admin can view all the users, something like shown on a wireframe below.
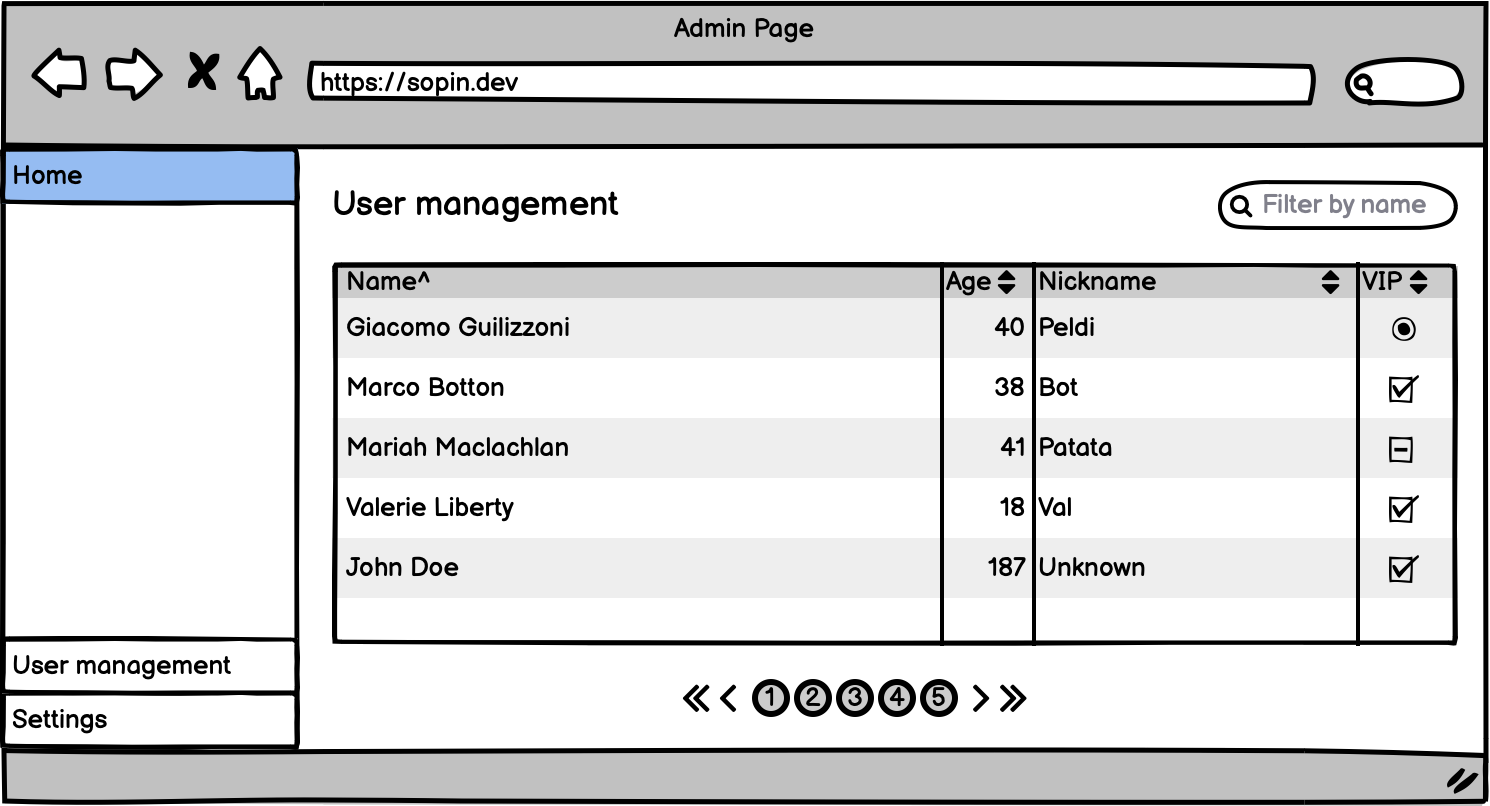
You could be wondering what can go wrong with such a simple use-case and the answer is almost everything!
Sorting
As you can see from the mockup, the UI Grid which is used to display the data assumes that if we click the title of each column then the whole table should be sorted by this column. Considering that the number of users can be quite large this operation should be done on a database layer, which means we have to force DynamoDB to do this for us. However, on UI we have four columns used for sorting, while our table has only one Sort key and DynamoDB is not able to sort items using anything except Sort key.
This issue can be solved by using Secondary Indexes which are very similar to materialized views available in most relational databases. For instance, we can add couple of Global Secondary Indexes (GSI) with redefined partition and sort keys, however, this approach has a lot of drawbacks, here are some of them:
- When we create a new index for a table, DynamoDB creates an additional copy of data, which increases storage cost.
- Added complexity is required to identify if we need to use the main table or one of newly created views to read the data.
Also, it provides only independent sorting for each field, but if we want to sort by name first and then by age, we are done...
Pagination
We also have page numbers on the mockup, since the number of users can be quite large to display it on one page. DynamoDB does provide a pagination capability for Query results. So, let's see how such paginated query to the index with partition key = Age and sort key = Nickname may look like:
1 | aws dynamodb query --table-name Users \ |
The result of such query would look like following:
1 | {"Count":5,"Items":[ |
Please note, that we did not specify a page number in the request because DynamoDB doesn't have anything like that, we only passed page-size parameter to define the size of the page. Hence, we did not receive anything about page number in the response as well. The database only returned LastEvaluatedKey to let us know where to start our next query to get the next result page. Therefore, it is impossible to implement pagination with page numbers on DynamoDB without resorting to "dirty hacks". There is a good explanation on how to implement such pagination on Stackoverflow, but all of the available options are not natively supported by the database, so they come together with all the corresponding consequences, like performance degradation, cost increase etc.
Filtering
Now, when we know about challenges with sorting and pagination, it is time to look at the most trickiest case related to filtering as it is applied on top of those things discussed previously. But first, let's remind ourselves that it is impossible to apply filter conditions on partition key, so if Name is our partition key and we want to filter by Name, there is no chance to do so without using another index.
However, this is not the end of the story... Filtering is always applied on top of Query result. This means if we apply filter with the query described above:
1 | aws dynamodb query --table-name Users \ |
Then we get only two results even though we clearly stated that we want to get five of them:
1 | {"Count":5,"Items":[ |
So, in order to get pagination working together with filtering for display purposes we need to implement a custom logic on top of DynamoDB to append results from multiple calls.
Is it usable at all?
It is for sure usable for many use cases. There are multiple articles published about this topic, so I will not dive deep into this area. For instance, you can check:
- Amazon DynamoDB: Ad tech use cases and design patterns
- 5 Use Cases for DynamoDB
- Real-world use cases for Amazon DynamoDB
- Reddit: Real world use cases for Dynamodb
From my personal experience I used DynamoDB for storing billions of discount codes as part of an enterprise discount generator, it was also used to store offers and orders in order submission systems developed for one of the major Canadian mobile operators, and some other systems. DynamoDB was undoubtedly a great choice for all of these use cases.
Conclusion
With that said, should DynamoDB be your default database choice? Probably no, as in my opinion there is no such thing as a default choice in architecture.
DynamoDB is a great database that can be used successfully for an enormously large number of use cases, but it has its own limitation as well and today we reviewed some of them based on a simple example. I used DynamoDB for many of my architectures and it is a great tool that must be added to your arsenal if it is not there yet, however, you should always remember to assess the tools you are going to use before jumping into coding. I will sound like a broken radio, but I am going to repeat myself for the umpteenth time, every architecture must be based on requirements and those requirements include architecturally significant quality attributes, limitations and business requirements. I wish you the best of luck in your architectural journey and I hope that this article will be of use.
PS: Please share your experience with DynamoDB and other databases in the comments below, it would be great to learn more about other successful and maybe not so successful stories. Best of your stories may be added into the article.