
Microservices is a common buzzword these days and everyone wants them just because "I've heard it is cool and modern". It became a de facto standard for the new applications, although not everyone understands what are the real benefits and disadvantages of Microservices architecture. During my career I've seen many implementations that were far from ideal, therefore I decided to write this article in the hope that it may help you to avoid some of the common mistakes.
Why microservices?
Software systems have been evolving throughout history. First applications were just a sequence of bites fed to a computer using different physical mechanisms such as punched cards. Going forward higher level programming languages simplified the process of software creation, however, those languages were mostly "procedural" and the resulting code has often looked like a long spaghetti.
Eventually engineers realised that it is not that easy to maintain the "spaghetti" code and introduced abstractions allowing to decompose code into smaller pieces. This was a big step forward which gave birth to object oriented and functional programming languages.
With the appearance of the Internet, economic globalisation, the rise of cloud computing and new software availability requirements humanity faced another problem related to the constantly increasing load at the software and hardware components. Horizontal scaling of large monolith applications was quite expensive, since they often required a lot of resources, such as memory, storage and computational power. During that time (2004-2005) engineers realised that large monolith applications can be decomposed into a number of smaller applications running in parallel, so they can be scaled and maintained independently. And that, colleagues, how the world met microservices.
As you could figure out by now, the main benefits of microservices are:
- Scalability - services can be deployed and scaled independently. They may have different scaling thresholds (i.e. conditions), different release cycles, etc.
- Availability - is not a direct benefit of microservices since well designed monolithic applications can achieve the same availability numbers as microservices, but I personally think it is easier to achieve high availability with decoupled architectures like microservices.
- Distributed development - allows smaller teams to work on different system components independently without even knowing what other functions the application provides. It has its pros and cons since it allows to reduce the ramp up time for the new team members and, at the same time, it limits their knowledge about the whole application which may backfire later on.
There are a couple more arguable benefits that were not listed here, but the ones above make the real difference.
However, we all know that all the benefits always come with a price, for example, by splitting a single application into smaller ones we force them to communicate between each other over the network which increases latency. Managing transactions becomes very complex, error prone and often requires techniques like Saga pattern. Your DevOps practice must be quite strong to be able to build a proper microservice-oriented CI/CD pipelines, in fact the term DevOps arose as a result of agile evolution and partially because of the complexity related to managing microservices. And there are a lot of questions regarding what "micro" actually means and how to define the boundaries of the services as well as their responsibilities.
In this article I will try to discuss some mitigation techniques that help overcoming all the difficulties and squeezing more benefits out of your microservice architectures.
Monolith to microservices
Most companies I worked with already had working applications that they wanted to modernise, and because their management had heard that microservices are cool they wanted us to take their existing applications and seamlessly modernise them into microservices.
There are tons of articles explaining how to do that, for example, I do like the one written by Zhamak Dehghani on Martin Fowler's blog, so I am not going to spend much time here.
In short there are three types of migrations that I encountered in my life:
- Big bang - is when we simply rewrite everything to achieve a desired state. This approach is extremely risky, but sometimes the benefits outweigh the risks. I would recommend being very careful using it.
- Evolution - is when we evolve an existing application into a newer one and the first steps do not necessarily look like microservices. It is much safer than "Big bang" migration, but has its own pros and cons well described by Zhamak Dehghani in her article.
- Strangler fig pattern - is a subtype of evolutionary migration that assumes extracting microservices from the monolith one by one. There is a very good description of it published by Martin Fowler, so we will not dig deeper.
As you could see, it doesn't matter whether we migrate legacy application to microservices or create a new microservice application from scratch, we need to answer the question "what is micro in our case?" and define the responsibilities as well as boundaries of each service, and this is what we will discuss next.
Common decomposition strategies
There are many ways on how to decompose microservices that depend on personal experience, size and complexity of the application, requirements and constraints, etc. However, there is no definitive answer which one of decomposition approaches is best. The same method may produce very different results depending on the context, which makes decomposition more an art, then something else.
Every decomposition strategy starts with requirements and the best way to document them is to follow Agile's User Story approach. For example, let's review a couple of requirements for the new online retail store.
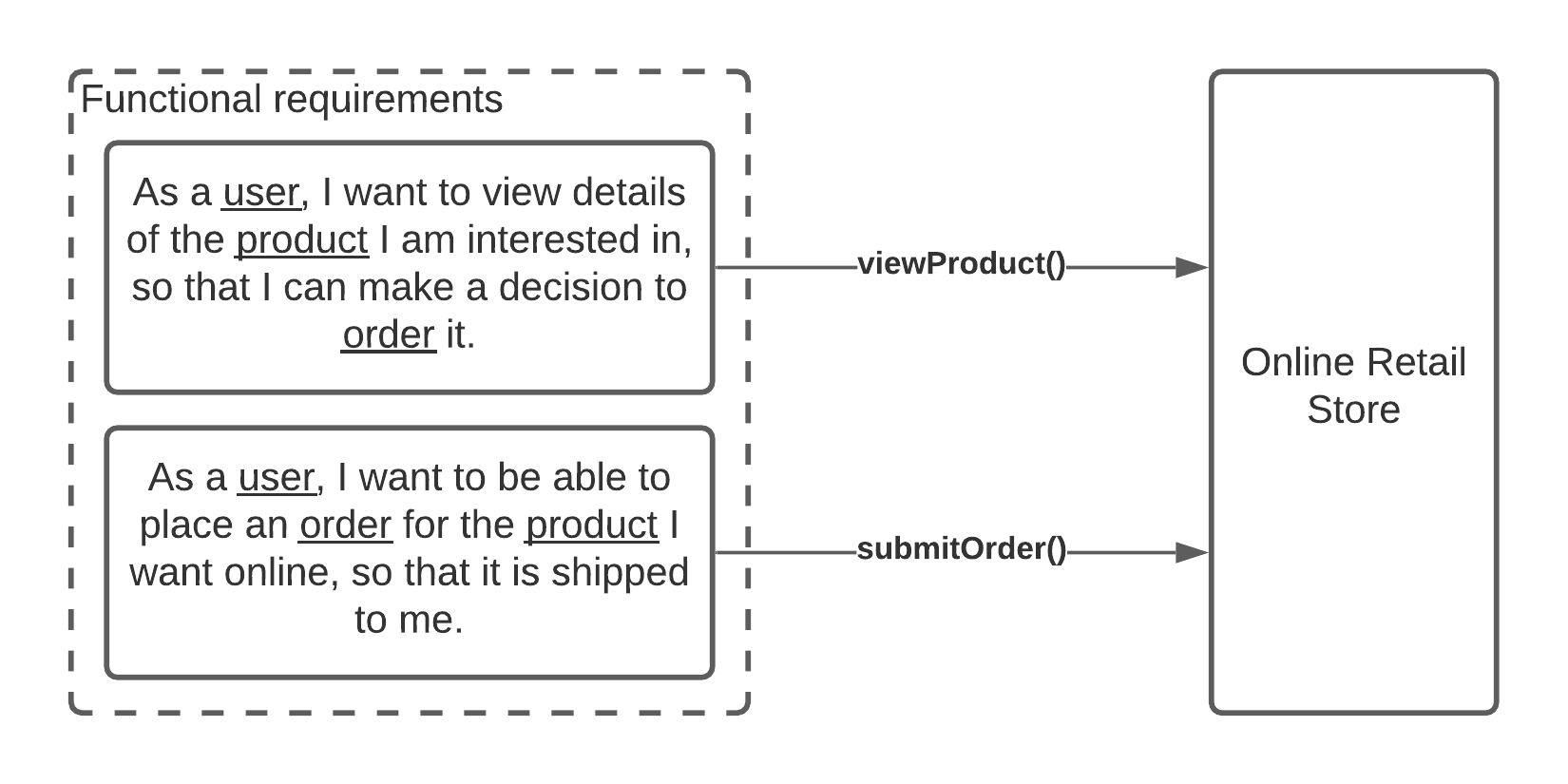
These are the very basic requirements, however, even those can be extremely useful while decomposing a microservices application.
The requirements can help not only to identify the services we want to create, they can also hint what operations those services should perform. You can also use Gherkin language to define acceptance criteria for your user stories to clarify all the details about requirements and service operations.
Sub-domain decomposition
If we look at the example a bit closer, we can see the nouns used in the text, those are our hints. For instance, we can see that both requirements tell us about a user. In the retail industry we may think of at least two types of users: registered ones and guests. If the user is registered, it means we need to store and manage her information such as name, email address, delivery address, etc. Guest users are a bit more tricky, however, to be able to provide a seamless shipping experience we still need to capture and store some user information. As a result, it would be very logical to have a separate service that operates users. In this case user is an entity. The very same logic can be applied to other nouns as well.
This method was well described by Eric Evans in his book Domain-Driven Design: Tackling Complexity in the Heart of Software. The main idea behind it is that each sub-domain has its own set of entities, those entities are entirely located inside the respective sub-domains and they leave sub-domains only using predefined façades or transformers. Another important part of sub-domains is a ubiquitous language that allows modelling a subject area in terms of each sub-domain. From a technical standpoint, a fully identified sub-domain represents a service.
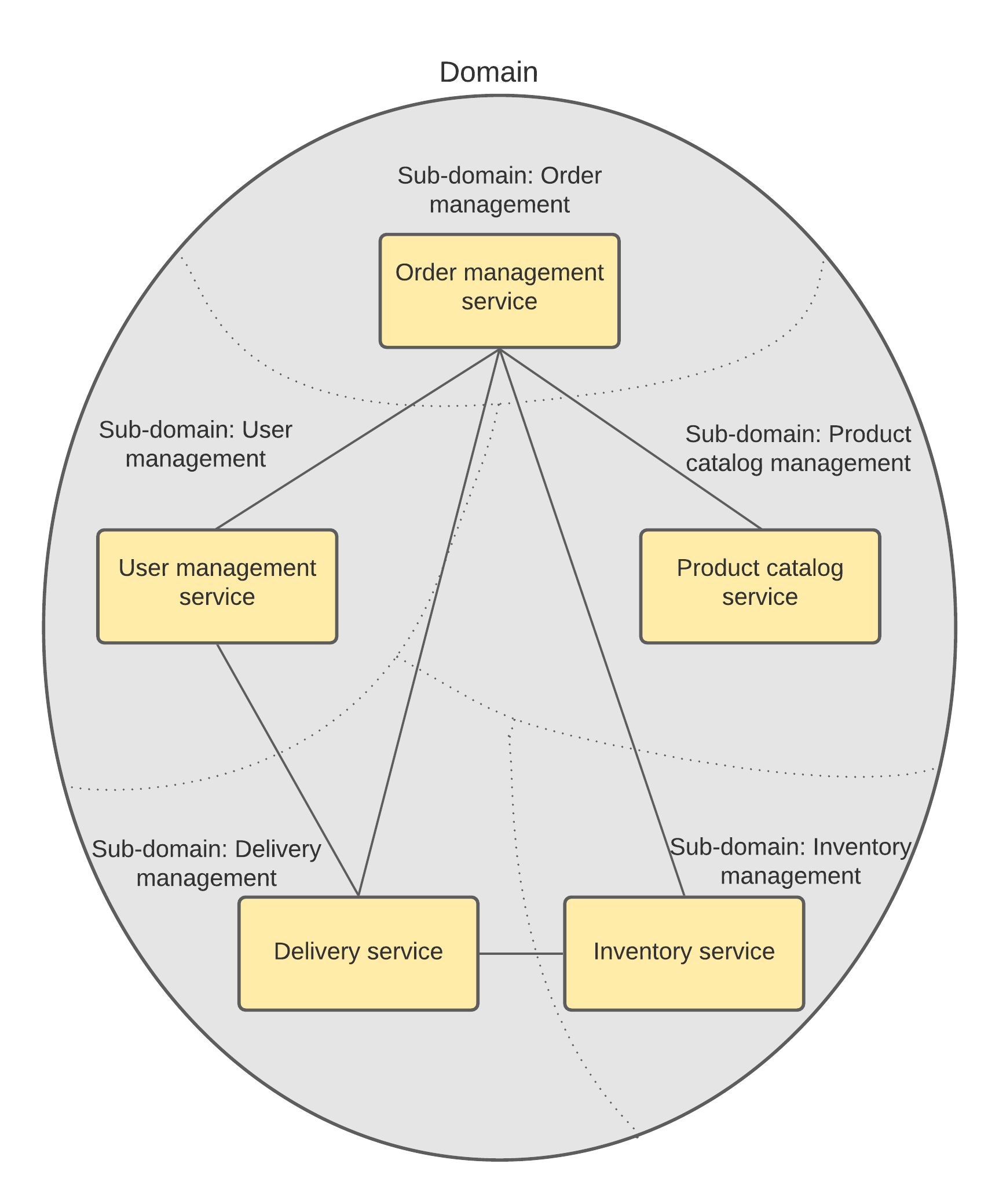
Sub-domain decomposition strategy assumes identification of entities and consequent grouping of these entities in services that operate them.
From my experience, this approach can be interpreted differently and if applied without proper thinking it may result in a tight coupling between services which is known as distributed monolith. We will review this problem in detail later in the article.
Capabilities strategy
Another common decomposition strategy is to identify not only domain entities, but the whole business domains or business capabilities around them. Earlier we agreed that identification of an order entity can lead us to having a service that operates this entity. However, an order can be much more than just one entity since we may need to manage a lot of related meta-information and related entities. For example, an order itself may contain information such as order number, order date, the list of ordered products or services, etc. In some context though orders are tightly coupled with the delivery information as well. If we were to follow the domain model decomposition strategy, there is a good chance we would end up with two services to manage these entities: order and delivery. But as it was already highlighted, in some contexts, such separation would result in a data split and we would have to pay a certain price related to additional network latency, increased resource consumption, decreased availability in case of synchronous communication, etc., which may force us to combine those two entities into a single service that belongs to Order fulfilment business capability.
Such decomposition logic assumes that to identify the boundary of each service we need to identify business capabilities first and assign a separate service to each business capability instead of sub-domain since sub-domain may not cover a business capability fully, or vice versa.
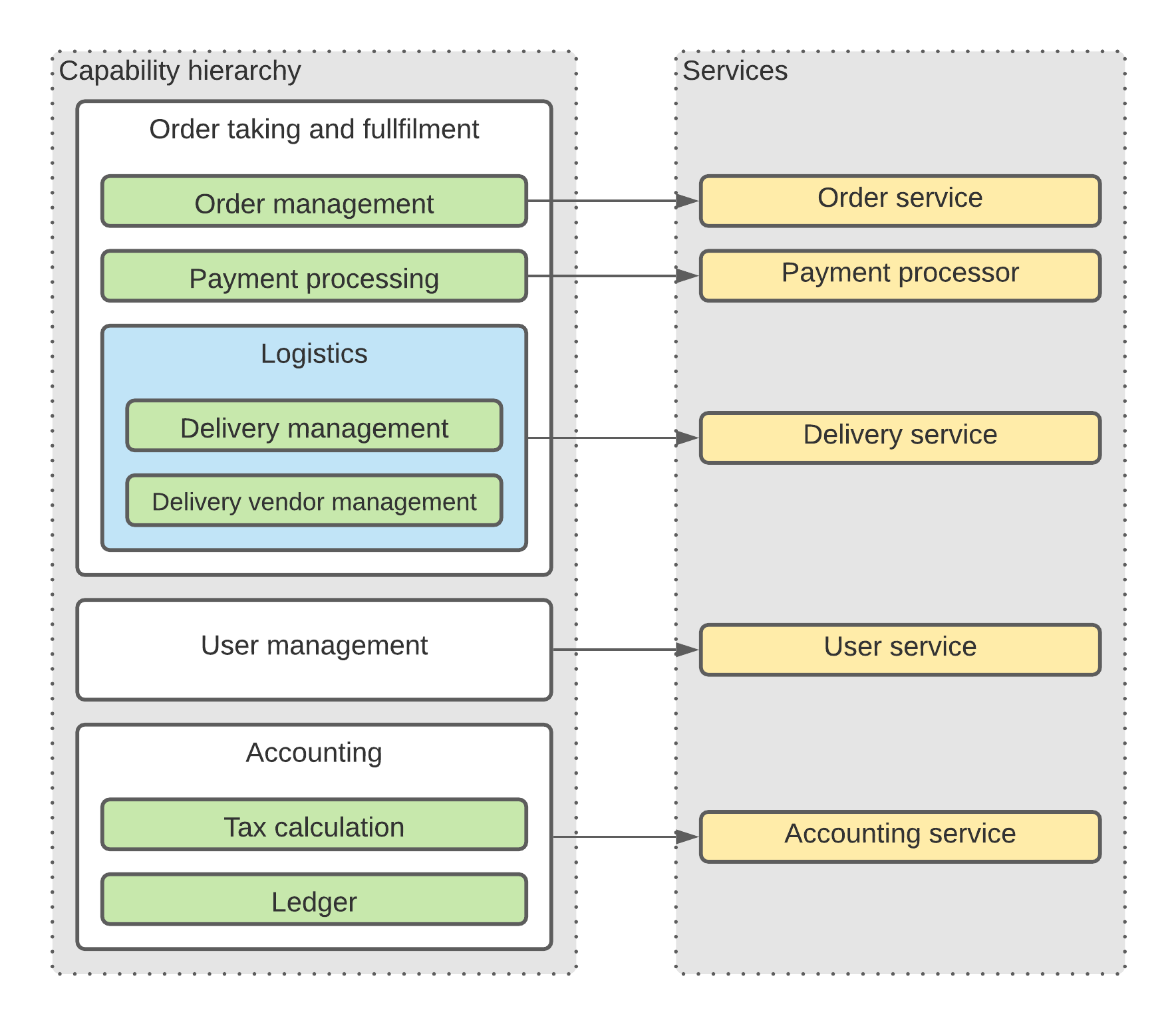
The main idea behind business capabilities decomposition is to group functionality into services based on what those services are responsible for.
Capability decomposition approach is quite beneficial, but it can result in unnecessary large services or unclear service responsibilities if not used properly.
What can go wrong?
I have already mentioned some of the potential problems such as data splitting, distributed monolith, etc. Some of these problems may arise because of poor design, while the others are related to operations, planning, project management, etc. Let's review some of the common mistakes in detail.
"Fat" services and transaction management
Several years ago I was starting a pretty interesting project related to the insurance industry. We have been working together with another vendor which was responsible for the creation of "microservices platform", i.e. template of microservices and some operational components around them, while we were responsible for the overall architecture and a business logic implementation. After a couple of months on the project we found ourselves in the middle of a very strange argument related to the microservices decomposition strategy. The problem was related to transaction management. Since the client was an insurance company, transaction management has been very important to them and they wanted to ensure that the data stays consistent.
Neither of the decomposition approaches discussed earlier provide this guarantee. So, how do we solve it? Does it mean that microservices are not usable for such use cases?
Well, there are multiple solutions for this problem, but not all of the solutions are equal. Some engineers may argue that the best solution is to design microservices in a way that the transaction never leaves its boundaries, i.e. design microservices around transactions. This approach can be misinterpreted as a Domain Driven Design, since we, kind of, design around entities.
Let's try applying this approach to our online retail store. When the user orders some goods or services we need to create an order, update the user and, in case of order-delivery coupling situation, we may need to update the delivery information as well. All of that needs to be in sync, so we can consider it a single transaction. As a result, we would end up with a microservice similar to the one shown below.
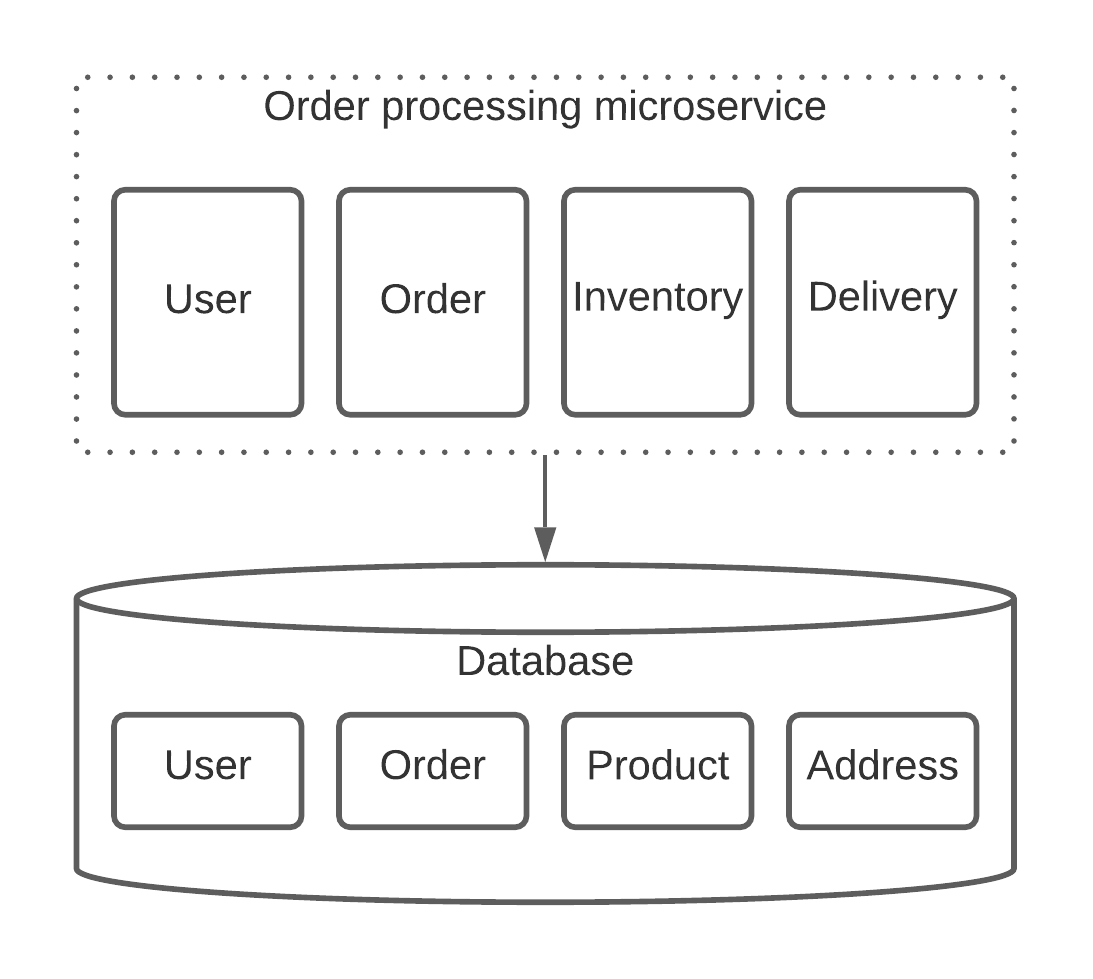
This is the exact solution which was proposed by our counterparts on the mentioned project and this type of microservice design was called a "fat" microservice. So, why is it a bad one?
If we design services in this way, we most likely introduce data dependencies which most likely will lead us to a shared database design, which is not that bad by itself, but introduces a bottleneck since we need transactions and transactional databases usually do not scale that well (yes Google Spanner you are an exception, but you have your own issues).
Another problem is that we lose all the logical boundaries among microservices. For instance, I cannot say for sure what the service above is responsible for. We have user-related functionality there, so nobody prevents us from implementing the whole user management there. With that said, why don't we simply implement everything inside this service and call it a monolith? There are many more problems with this approach, but I think you've got the idea.
Okay, we know that "fat" microservervices are not good, but what is? Transactions management is quite difficult with microservices, however it is solvable. One of the best practises in this area is Saga pattern. It introduces its own challenges since it requires much more effort to implement and is a bit complex overall, but it doesn't break the main principles of microservices.
Nano-services
As it is mentioned above, nobody can tell you what "micro" actually means. So, many people think that the smaller the service - the better, which is true in some cases, but not always.
I've had a project where one of our technical leads was fond of nano-services, and in general there was nothing wrong with it, except one thing. Their microservices were not containerized and each microservice has been hosted on its own VM, in addition, to maintain high availability, this microservice was replicated and each replica has had its own VM as well. By following this "nano-passion" the project ended up with an enormous infrastructure bill and had to be redesigned.
Even if you use containerization it is still better to think twice before designing super small services since each of them requires a certain amount of resources and the team has to spend some time developing, testing, configuring it, writing deployment instructions, etc.
If you are really into small things, then think about FaaS (Serverless).
Distributed monolith
Another potential issue that may arise as a result of either a very small or badly designed service is a distributed monolith. This mistake is one of the most common and it is a situation when services have hard dependencies on each other. The most obvious signs that you have a distributed monolith are following:
- Small change to application logic in one of system components causes subsequent changes in one or more other components.
- The number of parameters in the service APIs is constantly growing.
- Services share a lot of common code.
- Shared database could be one of the signals as well if not designed properly.
- Services become very chatty.
There are multiple reasons for this problem to cripple your code, for example:
- APIs designed without abstractions - I've seen API contracts that were mirroring internal data models. As a result of such API design you would have to change your API as well as all the services you integrate with this particular API whenever the internals of the service change.
- Long synchronous workflows and hard dependencies between services - I've seen this mistake made by a very senior engineers. For example, when service A performs certain operations and then calls service B to supplement the data with some additional info and service B is unavailable at the moment, it doesn't necessarily mean that service A should fail with exception.
- Your data is split between several microservices and in order to perform their functions these services have to constantly communicate.
There are many more reasons for this problem which can well be a separate book, so I am going to stop here.
Poor code optimization
Modern programming languages and frameworks bring simplicity, but they sometimes tend to turn off the common sense as well. In my career I've seen the situations when instead of optimising the code and tuning its performance my clients were simply scaling their services out. While this approach works for some time, it is not very sustainable. Let's think about services like WhatsApp, Meta(aka Facebook) engineers spend a lot of their time optimising the code since one suboptimal line of code may result in thousands of additional servers required for this code to operate due the enormous load. Such a simple mistake can potentially cost millions.
DevOps & SRE
As it was mentioned in the beginning of the article, DevOps is crucial for microservices platforms. Apart from having mature deployment practises, you should never forget about monitoring and alarming.
Monitoring can be considered as something very simple, I've seen many companies which relied only on things like heartbeats and error rates for their services. While it may seem as enough, I would highly recommend measuring everything you can. For instance, in the recent past I've had a production incident related to one of our storage services. This was AWS managed storage service with one master node and a couple of read replicas. We had a huge traffic spike and, even though the service itself was working well, it exhausted the network bandwidth on a master VM. As a result, the VM started throttling the network and the replicas became out of sync and started "cold" re-indexing. This process in its turn consumed the rest of resources and left the service alive, but totally unresponsive. Such incidents can be detected in advance, but without proper monitoring and alarming configuration you cannot notice it until your service stops responding.
Another useful practice is SRE. I won't go deep into this topic, but I highly recommend you look into it.
Conclusion
Microservices became a defacto standard for modern software development. They bring a lot of benefits, such as scalability, distributed development and many others, however, at the same time they bring an increased complexity and raise the bar for developers. Software engineers must think very carefully when designing microservices platforms to avoid the pitfalls described in this article. What we reviewed today is just a tip of an iceberg, but these problems are the most common and dangerous ones. If you have some other examples of suboptimal microservices implementation, please share your experience in the comments below, so we can learn together.