
About a year ago I was asked to join one quite interesting project with the task to help the project become sustainable in the long term. The project was developed within extremely limited time, resources and, due to internal politics, with almost no support from the customer's organization. It had many issues, but there was one that caught my attention, this problem was a presence of different stakeholders who represented different business units and all of them had their own requirements. Moreover, new stakeholders kept emerging with new requests. It was quite obvious that to make this thing work in the long run we had to come up with some kind of separation to prevent unrelated requirements from affecting each other. In this article I am going to explain the principle that I used, together with code examples and DevOps practices similar to those used on a project, so buckle up and let's get started.
What is Multitenancy?
Traditionally, multitenancy, in the world of software, means that multiple clients use sinlge application in a completely independent way, so their data is isolated and invisible to each other. However, in the world of large enterprise systems there are cases when your customers have their own clients and they want to provide their clients with the unique customer tailored design and features.
The main benefit of multi-tenant approach is that all tenants (customer tailored applications) use the same platform and core functionality, so you do not need to develop it from scratch for each of them or manage it independently. However, there is no silver bullet, and this case is not an exception as by implementing common functionality in one place we introduce some level of inter-tenant dependencies.
The best multitenancy is a separate application serving each tenant.
The decision on whether to implement multitenancy or live with separate applications must follow the golden architectural rule, i.e. it must be made based on requirements.
Now, when we know what multitenancy is and why we need it, we can discuss the implementation strategies that make multitenancy possible.
Inversion of Control
There are multiple ways on how to implement multitenancy, and one of these ways is inversion of control. However, the inversion of control itself is just a principle and can also be implemented differently. For instance, there is a very good blog post created by Martin Fowler explaining a couple of implementation options. I will propose another one, but first let's figure out what Inversion of Control (IoC) is all about.
The main idea behind IoC can be explained with a simple question: "Who/what does manage the main workflow of the application?". Traditionally we create software applications that are controlled by UI actions or API handler functions. As IoC name suggests, this principle inverts the flow of control. IoC assumes that there is a generic framework that controls custom elements from the application.
A software architecture with this design inverts control as compared to traditional procedural programming: in traditional programming, the custom code that expresses the purpose of the program calls into reusable libraries to take care of generic tasks, but with inversion of control, it is the framework that calls into the custom, or task-specific, code. (c) Wikipedia
I assume there were hundreds if not thousands of modifications of the simple "Hello World!" application created during the last century, so why don't we create another one using IoC? Yes, it is primitive, but it clearly demonstrates the principle, so let's dig deeper into it.
Because my project has been built using AWS serverless stack, i.e. AWS Lambdas, the applications had to start with as little time as possible, so we could not use heavy frameworks like Spring and we were limited by the abilities of Java 8.
The diagram below depicts class decomposition we are going to implement.
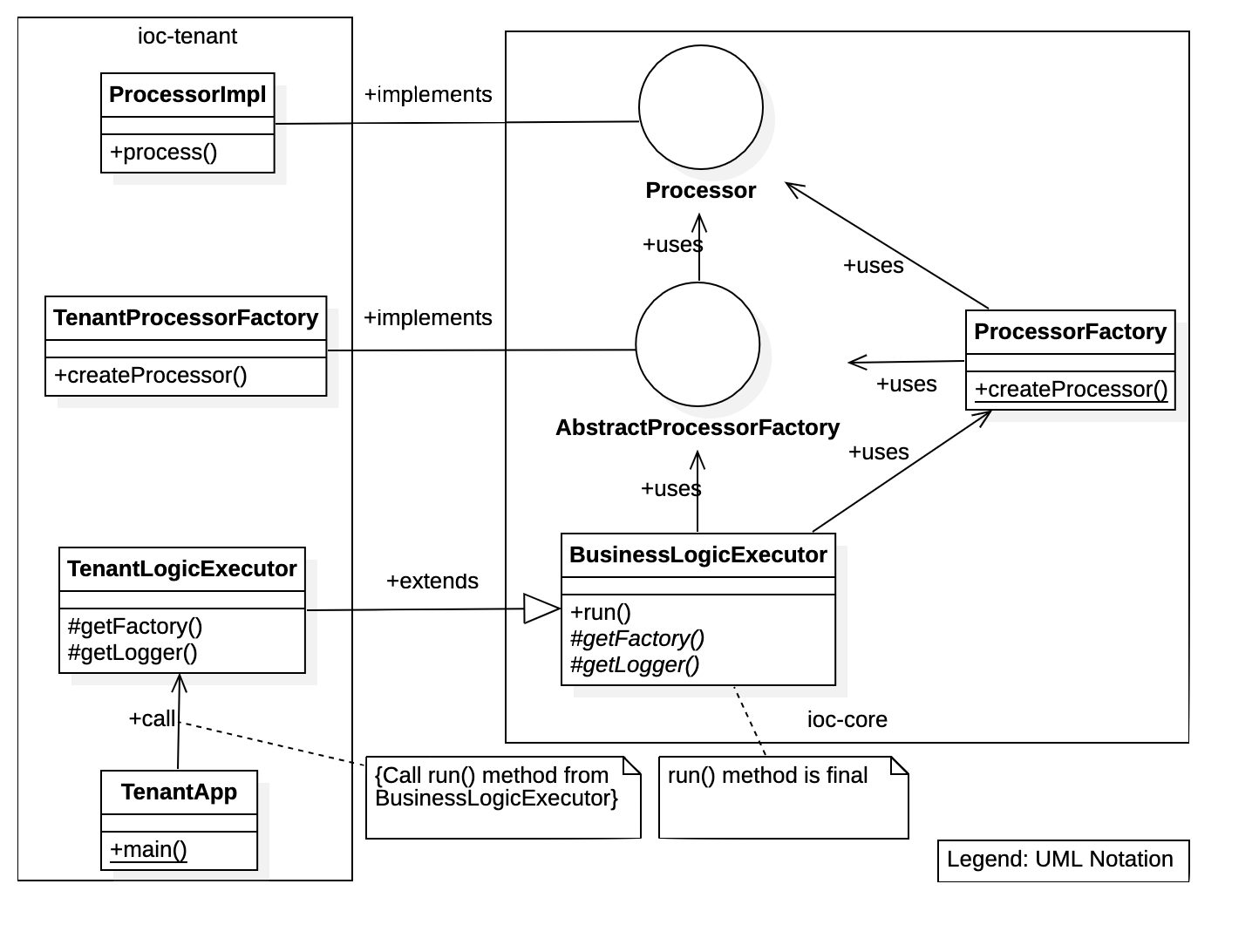
Generic framework aka Core
The idea behind implementing generic framework is to make it as flexible as possible while keeping main workflow logic inside. To achieve mentioned qualities we will create a class, let's call it BusinessLogicExecutor, add run function into it (the name has been chosen for demonstration purposes) and implement the main workflow of the application in this function. However, let's not forget that we want to keep the implementation flexible and that the framework must be abstract, so we will leave this class for now and get back to it a bit later.
To keep the framework abstract we can use Abstract Factory Design Pattern. In order to do that we need to create an interface, like the following one:
1 | package dev.sopin; |
Please note that the function createProcessor returns Processor object which we do not have yet, so let's create it as well:
1 | package dev.sopin; |
In our case Processor is also an interface that has a single function in it. This interface can be extended with additional functionality, but current implementation suffices demonstration purposes, so we will keep it simple.
Considering that the workflow is contained in the framework and should be executed in it as well, we need to have a possibility to instantiate Processor without knowing its implementation details. It can be done with another static factory:
1 | package dev.sopin; |
This class can be eliminated as in the example it provides little value, however, in a real-life project it may contain an additional logic. There are many possible ways of implementing similar things and this is one of them. For instance, you can also consider a Strategy pattern to add even more flexibility.
Now, when we have all the foundational work done, we can get back to BusinessLogicExecutor. As you remember, the idea is that this class implements the workflow inside run function, but allows extending the logic with custom implementations. To achieve this we will make run function final to prevent it from overriding and we will make the class abstract. Also, we somehow need to access the abstract factory implementations, which will be defined on a tenant's side. To do that we can add another abstract function getFactory, so our class will look like this:
1 | package dev.sopin; |
However, we cannot simply use this code in tenants as we may have many applications using it and simply copying the code everywhere or implementing everything on top of it in the same source code repository doesn't solve the problem. To truly decouple our framework from possible implementations we need to make it distributable, i. e. pack it into a JAR file and distribute via artifact storage. In the production environment I implemented this step using JFrog Artifactory, but for simplicity we can use local Maven repository. We can do all of this by creating a Gradle project with the following build file:
1 | plugins { |
and settings file:
1 | rootProject.name = 'ioc-core' |
I have an explanation of how to create Gradle projects in my previous article Running AWS Lambda written in Java with Docker .
Once the Gradle project is created we can execute gradle build and gradle publishToMavenLocal commands to assemble the artifact and upload it into the local Maven repository. You can find full framework implementation in my IoC Core GitHub repository. Now when generic framework artifacts are built and distributed we can start creating a tenant.
Tenant's implementation
As we already know tenant's code is dependent on generic framework and has to implement missing pieces to make the whole implementation work. Therefore, we need to import the library we created earlier using Gradle, and in order to that we will create a new Gradle project with the following build configuration:
1 | plugins { |
Having the Gradle project in place we can move forward with the business logic. Let's start with implementation of Processor interface we defined earlier to provide business logic we want to inject into main execution workflow:
1 | package dev.sopin; |
In our case this is simply "Hello World!" function, but using this approach you can implement anything you want.
Another missing part of this puzzle is implementation of the Abstract Factory, so we need to add it:
1 | package dev.sopin; |
But how can we make generic framework aware of this implementation? Well, the answer is simple. We made BusinessLogicExecutor class abstract and provided an abstract getLogger method that is used by run function. So, we simply need to provide both of them with a proper implementation:
1 | package dev.sopin; |
With that done our implementation is ready, so we simply need to add a Main class to run it and enjoy the results:
1 | package dev.sopin; |
Please visit my IoC Tenant GitHub repository to find a complete version of this code.
To run this code you need to build artifacts using gradle build command, then locate the Jar file inside ./build/libs/ and execute it using java -jar ioc-tenant-1.0-SNAPSHOT.jar command. Here is the output you will see in command line:
1 | [INFO ] [main] TenantApp - Starting application... |
As you can see, first, second and fourth records are generated by generic framework from the main workflow, while the third line was injected by tenant's code.
This approach gives us the possibility to implement main application logic once in a generic framework and force all consumers to follow the rules set by it, meanwhile providing consumers an opportunity to inject custom logic in order to extend the main flow.
Described approach has many benefits, but it also introduces certain complications. For instance, instead of having one java artifact we have many with dependencies between them. As a result, we need to reconsider our approach to operations.
Operations
Sometimes, when people talk about operations, they mean only deployment and maybe monitoring, however, when we are working with a bit more complex set of artifacts that have internal dependencies we need to be thinking a bit wider. First of all, we need not to forget about the release process. Also, let's imagine that we have a generic framework and certain number tenants that use it. They can all be managed by one team or multiple teams, which mean that each of them should have its own release cycle, version management approach, dependencies, etc. In this case it becomes important to think about artifact lifecycle and distribution ways.
Release management and artifacts distribution
Release management process requires a lot of conversations and agreements. For instance, the team needs to agree on how the software version is going to look like, will it be X.Y.Z - where X - major version, Y - minor version and Z - patch version, or something else. Also the team needs to agree about conditions under which they increase each number in the verison. Another point that the team needs to discuss is what does each version include, i.e. if all artifacts of the particular product are versioned as a group or if they need to have independent lifecycles and be versioned separately, etc. There are plenty of resources on the Internet dedicated to these topics, for instance Semantic Versioning, so we will not be discussing them in detail.
Another point to consider is code management and branching strategy. We will not discuss these topics here as they deserve a separate article, but here are some links that you can check:
- The Best Branching Strategies For High-Velocity Development
- What Is a Branching Strategy?
- Adopt a Git branching strategy
- A successful Git branching model
- Introducing GitFlow
- Gitflow Workflow.
Apart from these decisions the team needs to worry about the release process itself as well. On my project we used GitFlow branching strategy, so we built our release process around it. I am not showing the exact process we implemented, but the one below can be used for production purposes:
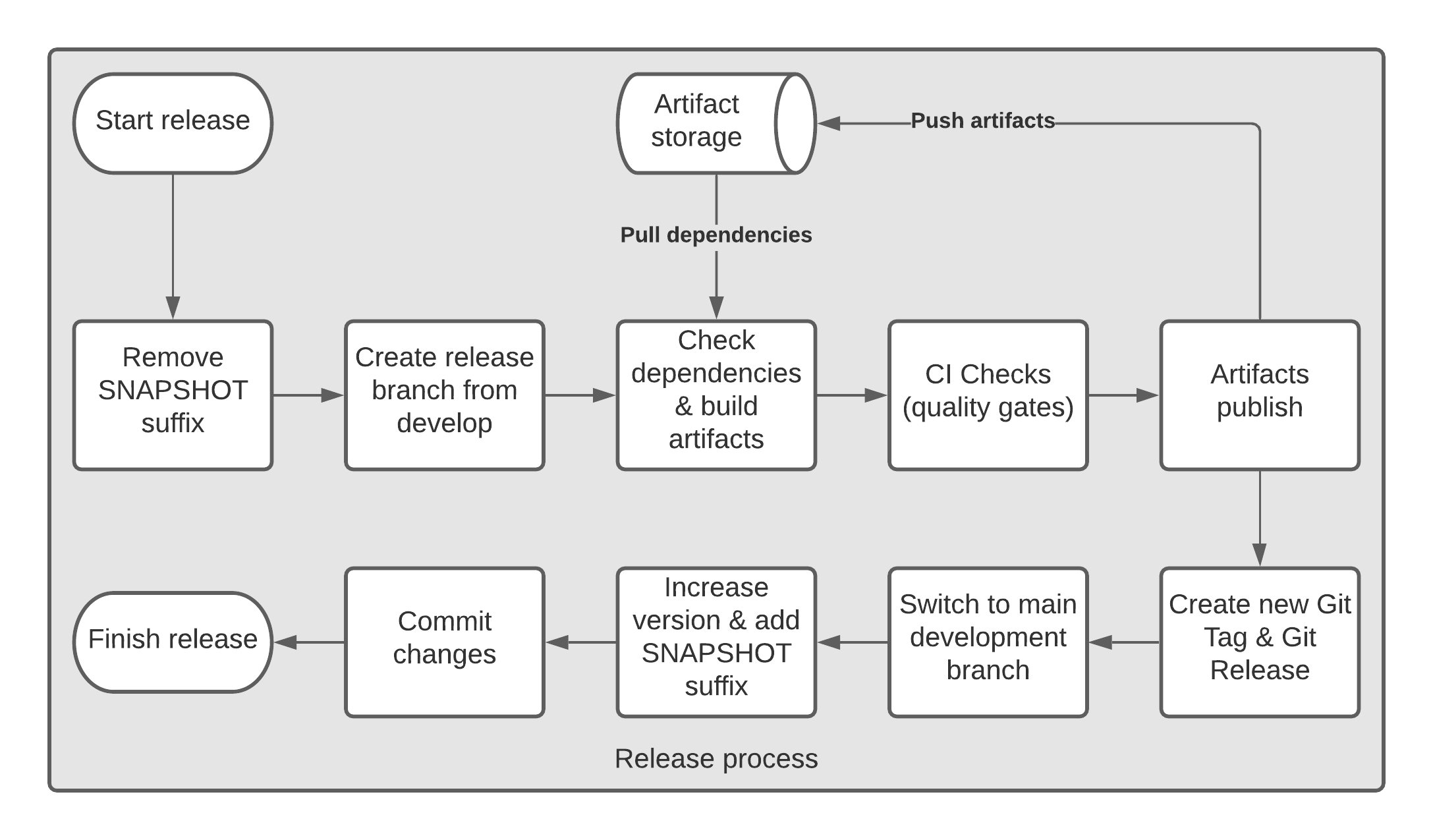
There are multiple sequential steps in this process, let's consider them one by one.
Most artifact management systems require artifacts to have a special suffix for artifacts that are still in development. Based on this suffix the system decides whether to allow multiple uploads of the same artifact or not, and does some other things. So, before we start releasing the product we need to remove this "in development" suffix (usually "SNAPSHOT").
We follow GitFlow branching, so it is also preferable to create a separate release branch for each release, to be able to "freeze" the code. And this is exactly what our second step is all about.
Next step assumes an optional dependency check and actual assembly of artifacts. Dependency check could be required in case you want to restrict your code of using some undesirable dependencies. For instance, in case of multi-tenant applications, you may want to prohibit releasing tenants which depends on the "SNAPSHOT" version of the generic framework. Build artifacts portion says it for itself, we simply build our code.
The following step is very often skipped by development teams, but it is a very important one. This step usually includes a number of different checks starting with simple Unit Tests execution and static code analysis, and finishing up with regression testing and other advanced validations that guarantee quality of your code.
Once all checks passed and we are sure that the code we are releasing works, and corresponds to our quality standards, we can publish generated artifacts to artifact management system (like JFrog Artifactory, Apache Archiva, Sonatype's Nexus, etc.) and create Git Tag and Git Release from the release branch.
Having all of the mentioned steps performed we conclude the release process, but we also need to prepare the development environment for the next iteration, so we need to switch back to the main development branch, increase version according to the agreements set earlier and commit these changes, so developers can continue working using this branch.
Note: version update can be done in a fully automatic mode. For instance, if it is a regular release we simply increment last digit, or, in case of major release, release manager (or any other person who performs release) can override version using release workflow parameters.
Deployment
Deployment topic is very broad and always depends on the requirements of each particular project. However, there are some generic prefered qualities of the deployment process that should be satisfied.
First of all deployment must be automated. There are plenty of orchestration, configuration and deployment tools on the market that can help with automation, for instance:
- Jenkins
- TeamCity
- Chef
- Puppet
- Ansible
- Teraform
- Spinnaker
- AWS CloudFormation
- GCP Cloud Deployment Manager
- and many many other tools.
Taking into account that all artifacts are being centralized in one storage, we can afford having an automated rollback process in case of deployment failure, which can be considered as a second "must have" quality of good deployment process. You can see an example generic of deployment workflow on the diagram below.
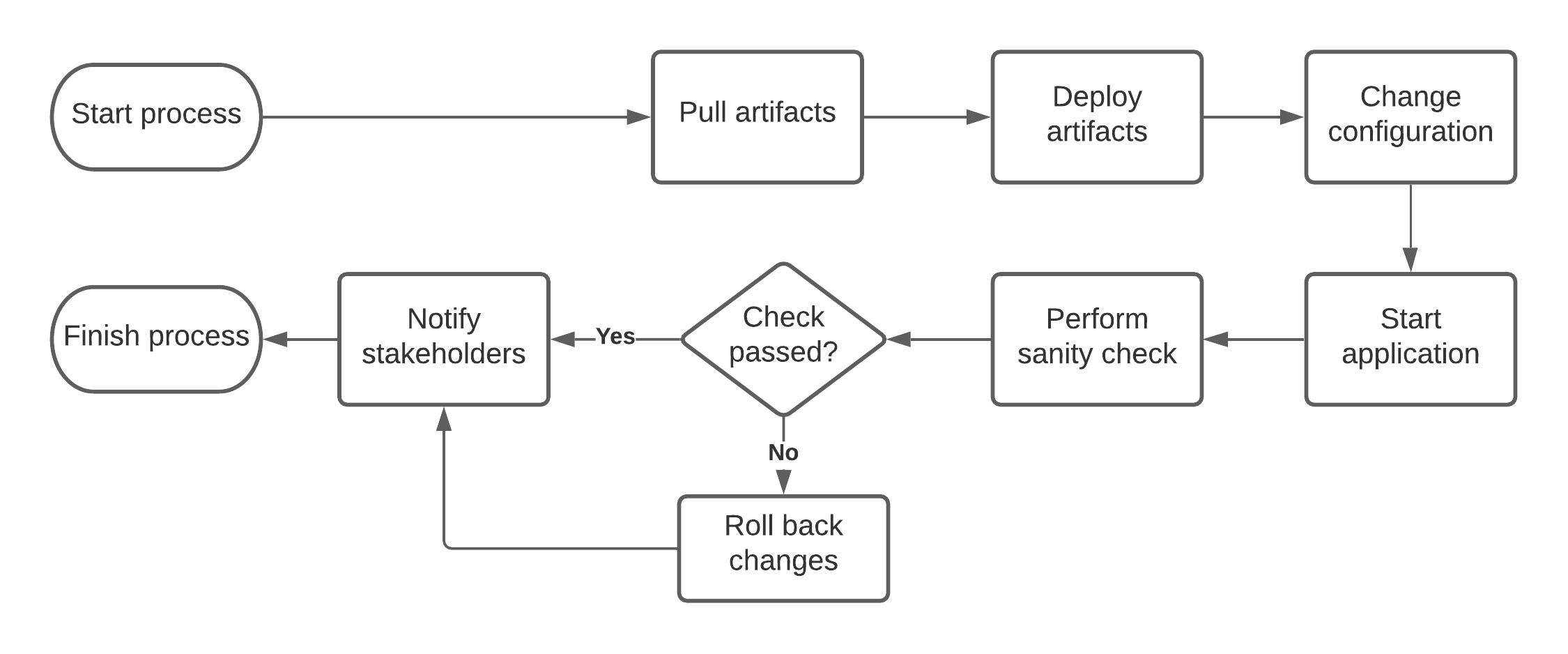
Last point that I want to discuss here is Infrastructure as a code. We already discussed that all the deployment, release, etc. flows must be automated, which means that we will be having another set of scripts, playbooks and other code artifacts in place. It is very important to treat all of them as a regular code, i.e. to follow coding best practices, use version control systems (like GitHub) to store code, and test it! It is the same code as everything else, so keep it nice and clean!
Conclusion
Proper implementation of multi-tenant applications can be tricky and requires a lot of effort from both, development and operations teams. However, if the teams follow well defined standards and use proper automation, all of those problems become solvable and eventually disappear. Even if you need to deliver a project in a limited time and you have to cut corners sometimes, you have to document all the decisions and create technical debt backlog, so you can catch up later. It is very important to establish proper development practices on a project as it almost guarantees long term sustainability and despite initial investments reduces project cost in the long run.