
During the whole history of humanity people were collecting, storing and organizing information of some kind. It all started with the ancient cave painting and evolved into modern distributed data storages that operate at petabyte scale. These are very different examples, but they both serve two basic purposes, namely storing and retrieving the information. Cave paintings evolved into manuscripts, then manuscripts evolved into printed books, which were stored in libraries, and every person coming to a library can get a book based on the request. Even though databases are much more complex than libraries, they serve a very similar purpose. They organize, store and provide data based on request. In this series of articles we will review how databases store the data, how the data is organized, what is the real difference between different database types and how they are used in practice. With this said, it is time to begin.
This series of articles was inspired by the best book I have ever read: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
The simplest database
The simplest example of a database is a text file with a couple of bash commands on top of it. For example, we can create bash file with the following content:
1 | #!/bin/bash |
It contains two functions db_put and db_get, first one appends a new record (i.e. key-value pair) to my_db.txt file, while the second one retrieves the record based on the key. What's interesting is that it can store almost anything, for instance JSON documents. Let's see how we can store some data there:
1 | $ ./db.sh db_put 001 '{"name": "Sergii Sopin", "location": "Toronto", "hobbies": ["Sport", "Cars", "Music", "Travel"]}' |
Note: You need to give the file proper permissions before running it using
chmod +x db.shcommand.
The underlying storage structure is extremely simple in this case, we have a single text file with lines being appended to its end. As you can imagine, the performance of our db_put is pretty good as it doesn't do anything except >>(append) operation. In fact, many modern databases use a very similar approach. However, if we look closer at db_get function, we can see that it scans all records in the file to find all occurances of a given key and then takes only the last one, which means that record retrieval time is proportional to the number of records stored. Such an approach would not satisfy modern database requirements. To solve this problem we need to have a separate data structure: an index.
An index is an additional data structure that is built based on primary data. Many databases allow you to create or remove indexes to speed up your queries (i.e. data retrieval based on parameters), but this luxury comes with its own price. For instance, as it was mentioned, index is an additional data structure, so it consumes a disk space. Also, indexes need to be updated when primary data is changed (i.e. record added or deleted), which decreases writing performance. Although, changing the index itself doesn't affect the primary data.
NoSQL: Hash index
The database we built previously is actually a simple key-value database, so we will start with this type of databases and indexes for them.
Please note, that there are more than one type of indexes that can be used for key-value databases.
Key-value stores are very similar to Dictionary (or HashMap or HashTable) data structures used in many programming languages. Let's review it in detail.
Hash Map
HashMap allows organizing data, so it is quickly accessible by the key. The biggest advantages of hash tables are:
- Operations like lookup, insert and delete take O(1) time on average (i.e. constant time).
- Most data types can be used for keys as long as they are hashable.
So, now when we know how cool hash maps are, let's see how they work. One of the possible implementations is Java HashMap, which is built on arrays.
Arrays let you access elements by an index, which in turn is represented by a sequential set of integers.
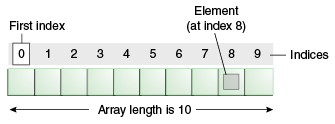
So, we can think of a HashMap as a wrapper on top of an array that hides array indexes and allows us to use flexible keys by applying a Hash function.
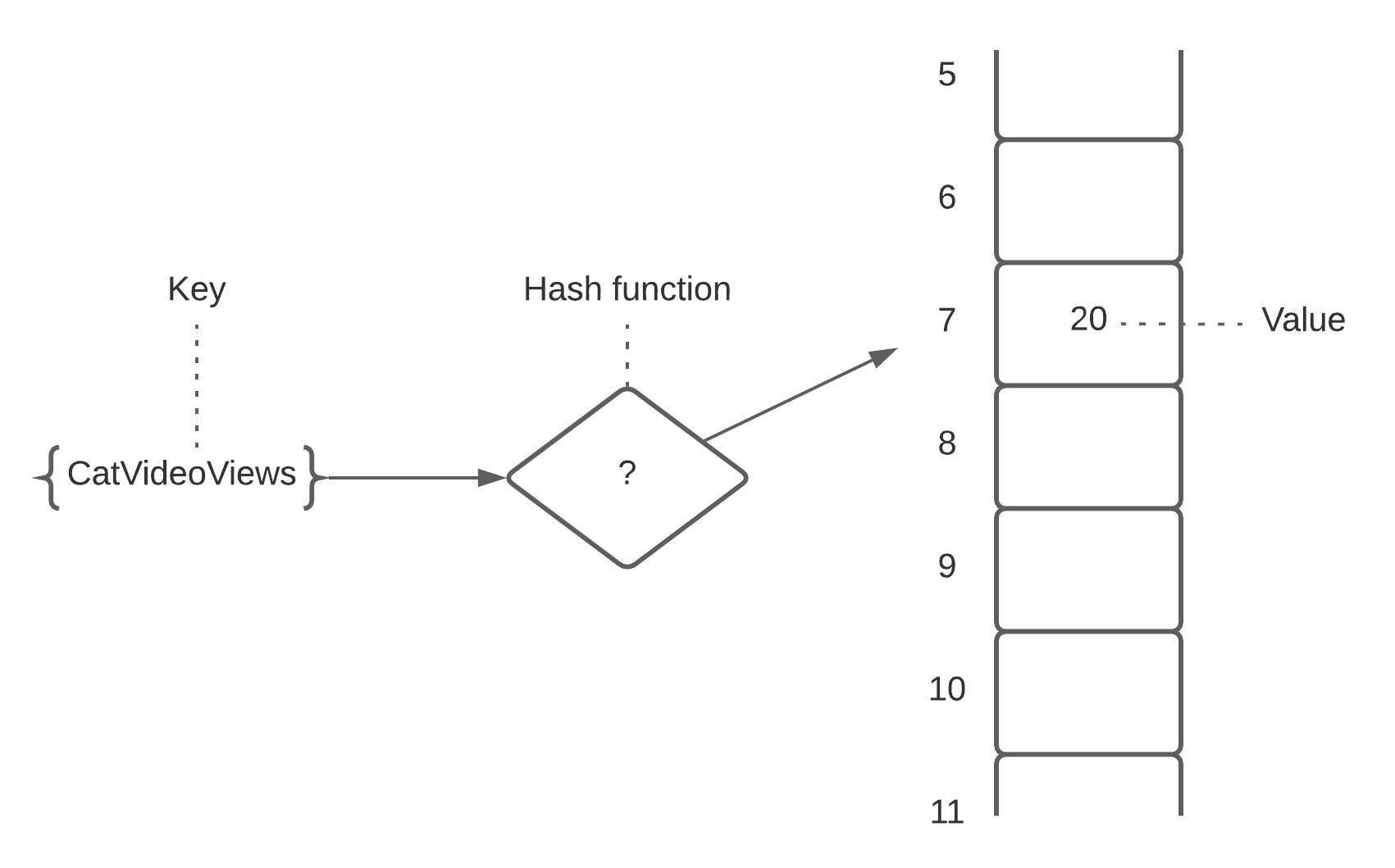
Hash function maps data being passed to it as a parameter to a particular number that, in case of a HashMap, corresponds to array index.
Hash index implementation
Considering that HashMaps work pretty well for programming languages, it would be reasonable to use them to index data structures on disk as well. So, in case the storage consists only of appending to a file, we can use in-memory HashMap to store key-value pairs, where HashMap key corresponds to our DB key and value corresponds to a byte offset of the DB record in the data file.
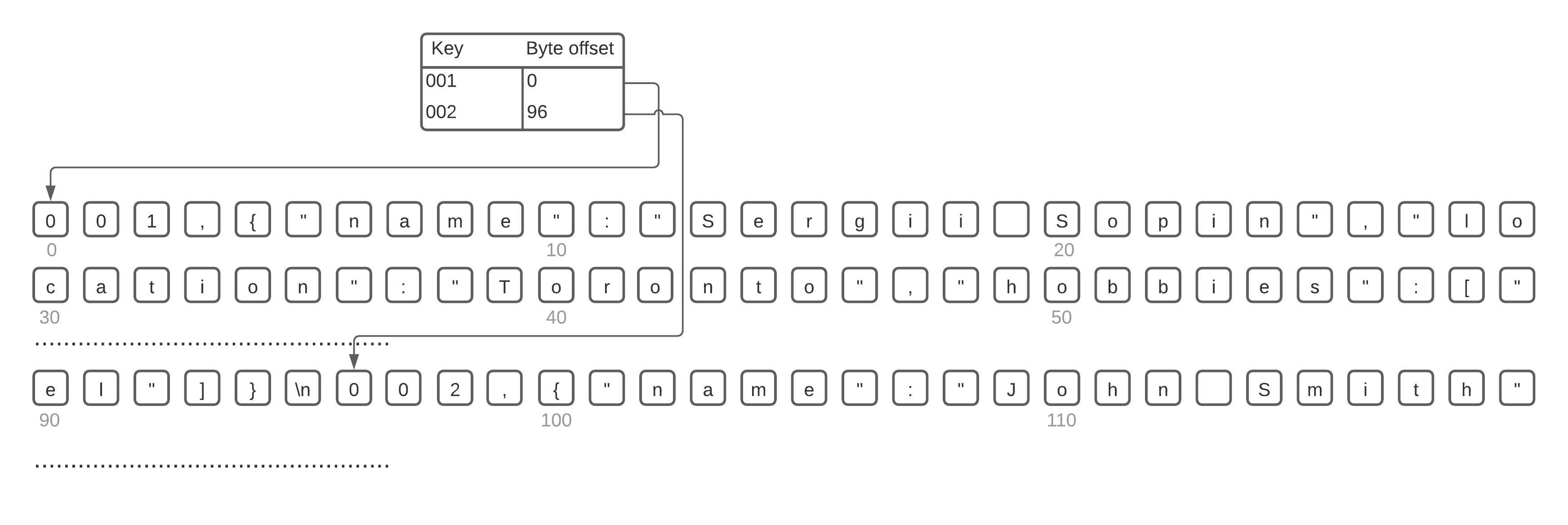
Such a simplistic approach is pretty viable and, in fact, it is used by Bitcask (storage engine used in Riak database. It is also worth noting that this approach has couple of limitations:
- All keys must fit into the memory, so if the dataset is large enough it may be a good idea to look for different storage options.
- Range queries are slow as we need to look for items one by one. It can be a problem if, for example, we need to retrieve all records with IDs between 00000 and 99999.
Although, this approach has a lot of benefits as well. For instance, appending the file and sequential operations in general are very fast and aligned with hardware architecture (HDD, SSD).
In real life, the Bitcask engine doesn't use a simple text file to store the data as it consumes a lot of disk space, so it is replaced with binary format which is much better in terms of disk space consumption.
Also, once we are speaking about disk space, I mentioned previously that the database file is appended only, so eventually we can run out of space. This problem is solved by the so called compaction process.
Copmaction process
The compaction process assumes that the database engine splits the appended log file (i.e. main storage) into chunks (or segments) with fixed maximum size. This means when the segment reaches some predefined size it is being "frozen" for new writes and the engine starts writing a new segment. So, for now we were able to reduce the size of each file, but we did not reduce the overall size, so how can we do that? Well, because we have multiple files now and we know that all of them contain a list of key-value pairs. Also we know that keys are not changing (they can only be added or deleted) often, but the values for those keys are updated frequently. Therefore, in the files we have a list of repetitive keys with different values, so it would be logical to merge them and leave only the last value for each key. That is exactly what the compaction process is all about.
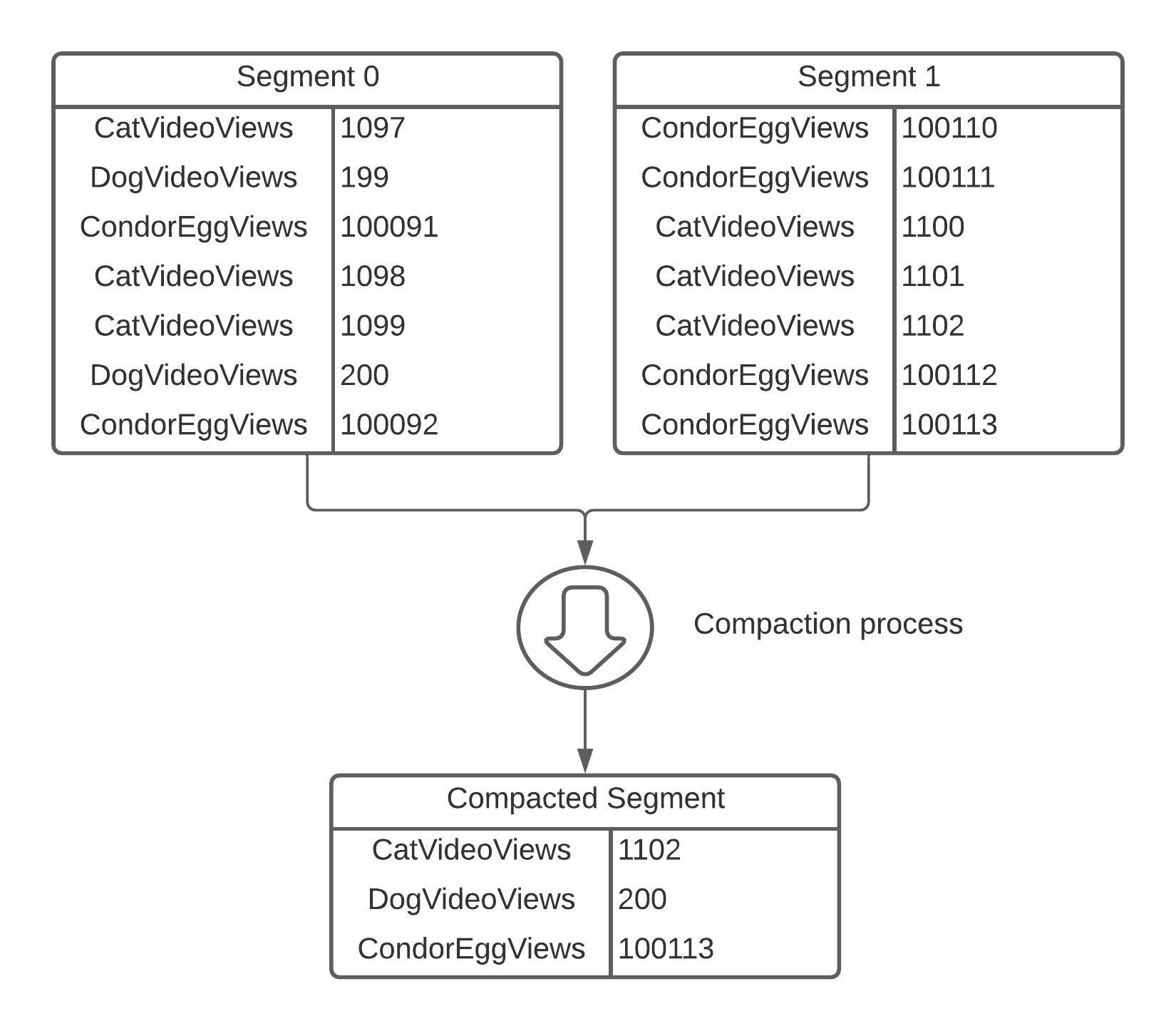
Usually, the compaction process is executed in parallel with the main database logic (i.e. in the background), so it does not affect main functionality. Database continues to serve writes to a new active segment and reads from all old segments by taking into account only the last value for a key. Once segments merge and compaction is complete, database switch reads to a new compacted segment and removes old ones.
If a user makes a request to delete the key and associated value, the database appends a special deletion record, that is sometimes called a tombstone, which tells merging and compaction process to discard all previous values for the deleted key.
Disaster recovery
As wise people say: “Something that has even a slight chance to happen in production, will definitely happen”, so we always need to keep it in mind and design our applications accordingly. In case database crashes in the middle of the write process we can end up with partially written records, to prevent such situations engines like Bitcask add another layer of protection in a form of checksums. Database assigns a checksum with each record and if checksum calculated based on data doesn’t match the saved one, then the database can either delete or ignore this corrupted record.
Also, as we have discussed previously, the database index is stored in-memory, which means that it will be lost after a DB crash and it may take a while to recover it. So, in order to speed up recovery time, Bitcask stores a copy of a HashMap corresponding to each segment on a disk, which can be loaded into the memory much faster.
Use cases
This type of database is used when there is a large number of writes for the limited number of keys, i.e. values are being frequently updated. For instance, the key can be a URL of a popular video, and the value is the counter containing the number of times the video was played. However, memory and hardware becomes cheaper and cheaper every year, so it is fair to say that we can use this type of datastores to host pretty large datasets.
Conclusion
Today we started our journey into the world of database engines and their internal organization. As we have seen, the databases can be quite simple while working pretty well. We discussed what a Hash index is and how it works. Even though this index is pretty simple, it has its own niche and is used in database engines like Bitcask. As every other system it has its own pros and cons, but it doesn't matter as long as it satisfies the requirements.
In the next articles of this series we will review much more complex database engines, indexes and storage mechanisms, so stay tuned! Part 2 of this series will be published soon, and there we will take a deeper look at another type of NoSQL indexes based on SSTables and LSM-Trees.